Changelog #18: High-frequency ingestion, handling NDJSON files and more product enhancements
High-frequency ingestion, handling NDJSON files, cascading partial replaces and more product enhancements

Here are just some of the ways Tinybird has been getting better in the last few weeks.
Feature preview: high-frequency ingestion
You can now ingest JSONs at thousands of requests per second to Tinybird using v0/events. Several events can be ingested in the same request. Learn more from our guide. This feature is in preview as it continues to evolve. Recent improvements include:
- A Data Source is now created automatically from a high-frequency ingestion stream. This is useful if you do not know the schema in advance.
- If new columns are detected in the stream then you are asked in the UI if you would like to add them to the Data Source.
Ingest complete lines from NDJSON files as strings
Sometimes you may want to ingest a complete JSON object as a string rather than parsing it into columns. To do this you define a column as column_name String json:$ in the Data Source schema. Each line in the NDJSON file will then be ingested as a string in the column_name column. This is very useful when you have complex JSON objects as explained in our docs.
Cascade selective replaces through your materialized views
If you have several connected materialized views then selective replaces are now done in cascade. For example, if ‘source’ materializes data in a cascade to ‘transform’ and from there to ‘target’, then when you selectively replace data in ‘source’, ‘transform’ and ‘target’ will automatically be updated accordingly. All three Data Sources need to have compatible partition keys since selective replaces are done by partition. Previously this was only available for a single level (‘source’ to ‘transform’).

More informative error messages
When you receive an error message using one of our APIs, you will now have a link to the relevant documentation in Tinybird’s docs. If ever you feel you would like more explanation in the documentation, just drop us a line with the details.
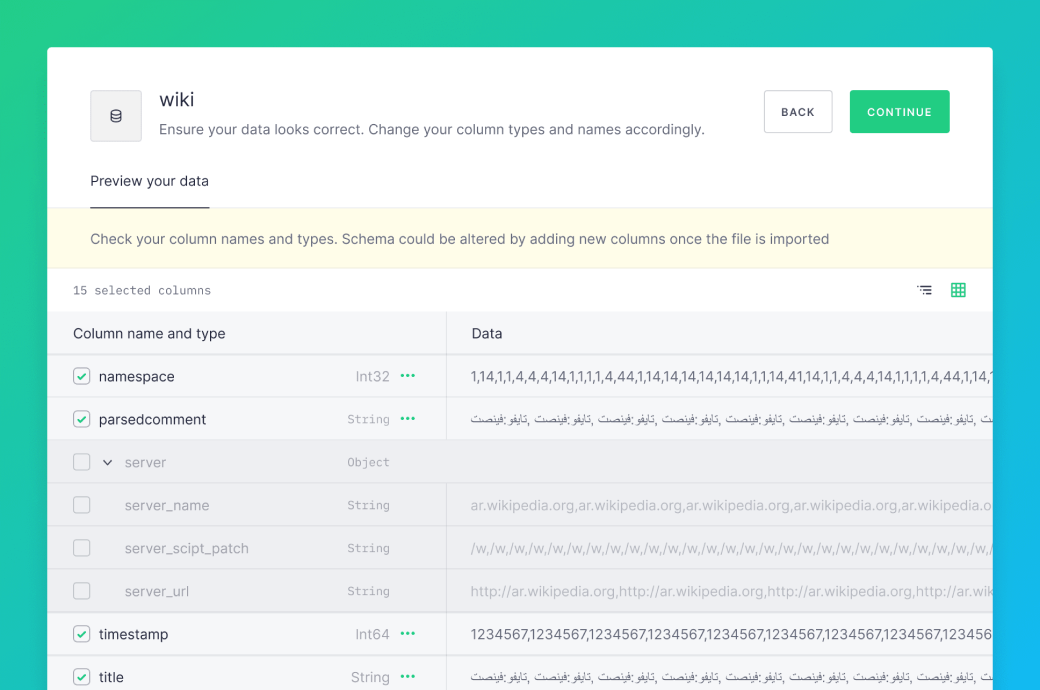
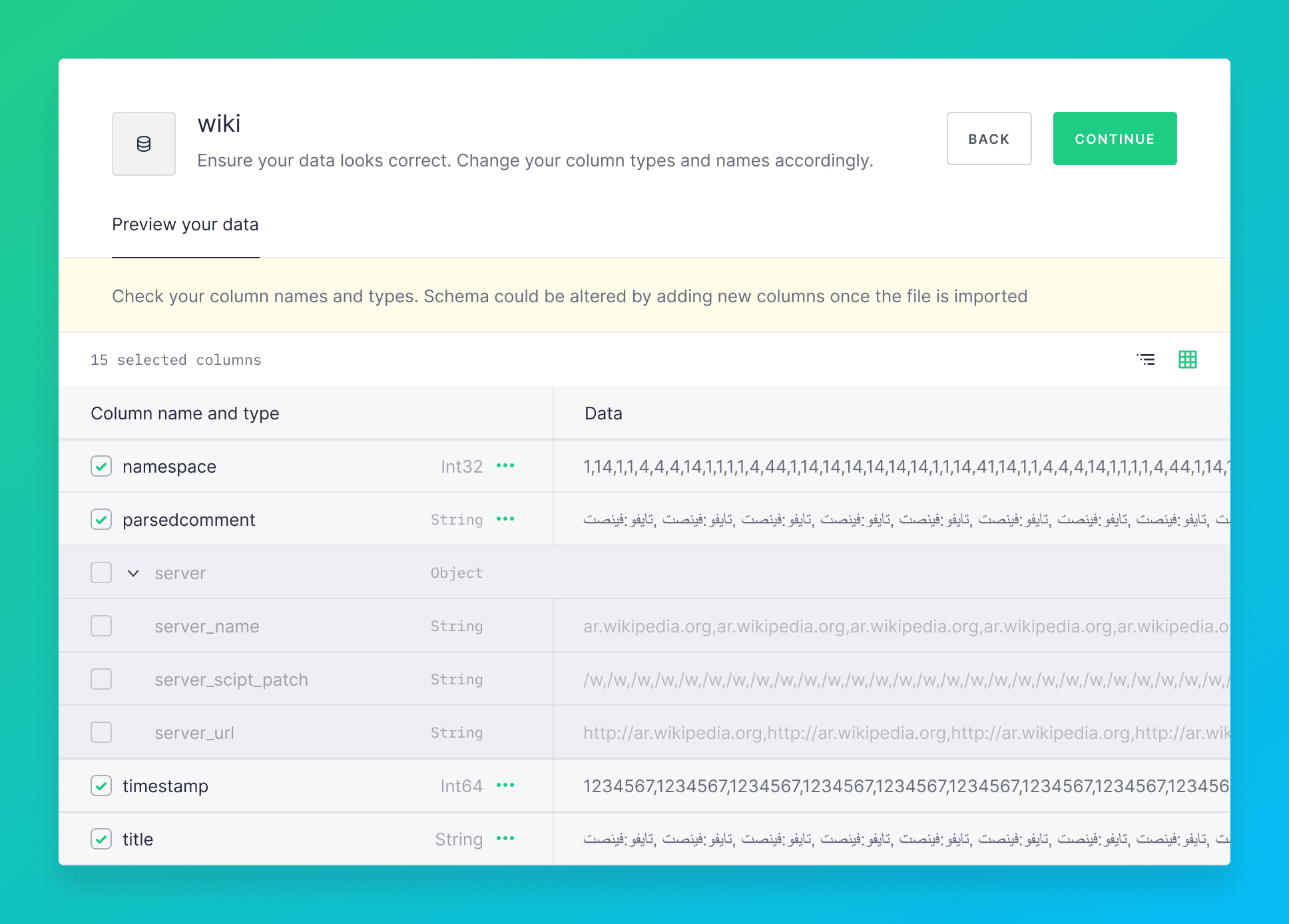
Tree view to ingest NDJSON data in the UI
A delightful feature when ingesting data from NDJSON through the UI is the tree view of columns to aid column selection. Columns can be deselected with one click. This is now the default view if the data has more than 15 columns or nested objects.
Export to NDJSON from the UI
You can now export data from your API Endpoint in NDJSON format, in addition to CSV and Google Sheet formats.
Kafka meta columns appear last when ingesting data from Kafka in the UI
Priority is given to your data so the six Kafka meta columns (topic, partition, offset, timestamp, key and address_city) are shown last when previewing your data and in the Data Source.
CLI updates
Check out the latest command-line updates. Examples are:
- Added a way to check the dependencies of a Data Source that would be affected by a selective replace
tb dependencies –datasource my_datasource –check-for-partial-replace. - Changed exit code to 1 (not zero) if there was a problem appending to a datasource.
- Removed explorations folder as it is not used and causes confusion.
ClickHouse
The ClickHouse project was improved to be able to KILL scalar queries. This means that rows read in scalar subqueries are now reported in the ‘query_log’. If the scalar subquery is cached (repeated or called for several rows) the rows read are only counted once. This change enables KILLing queries and reporting progress while scalar subqueries are executing.
Community Slack
Drop into the community Slack if you have any questions, doubts or just want to tell everyone what you are doing with Tinybird. Come by and say hello!