Iterating terabyte-sized ClickHouse®️ tables in production
ClickHouse schema migrations can be challenging even on batch systems. But when you're streaming 100s of MB/s, it's a whole different beast. Here's how we make schema changes on a large ClickHouse table deployed across many clusters while streaming… without missing a bit.


When we first released Tinybird, you could ingest a CSV file into a managed ClickHouse cluster, write an SQL query, and expose that query as a fast API. It was super simple. You had cron jobs extracting data from your systems as files and pushing them into Tinybird so you could build real-time APIs over the data.
If you wanted to migrate the schema on one of the ClickHouse tables in Tinybird, you could just stop your cron job or do the work between runs. Depending on the ingestion frequency, you could have hours or days to do the schema change, deploy it, backfill historical data, etc.
Batch is easy.

A lot has changed since those early days. Now, basically every Tinybird customer is using a streaming connector to write data to Tinybird in real time. Some of our customers ingest millions of events per second using Kafka, and many others use our Events API to stream tens of thousands of rows per second directly from their applications.
Streaming is hard.

Tinybird data projects that have several moving parts:
- Ingestion. You create Tinybird Data Sources, which pair managed ClickHouse tables with fully integrated ingestion connectors from sources like Apache Kafka, Confluent, Redpanda, Kinesis, BigQuery, S3, etc. Like any ClickHouse table, the schema gets defined on creation.
- Transformation: You then create Pipes, which are chained nodes of SQL that transform your ingested data, performing filtering, joins, and aggregations in real time. You can create Pipes for Materialized Views, Copy Jobs, or…
- Publication: You publish your Pipes as Endpoints, providing the output of your transformations as a low-latency REST API.
- Consumption. Finally, you integrate those Tinybird APIs with your user-facing applications which could make thousands of concurrent requests every second.
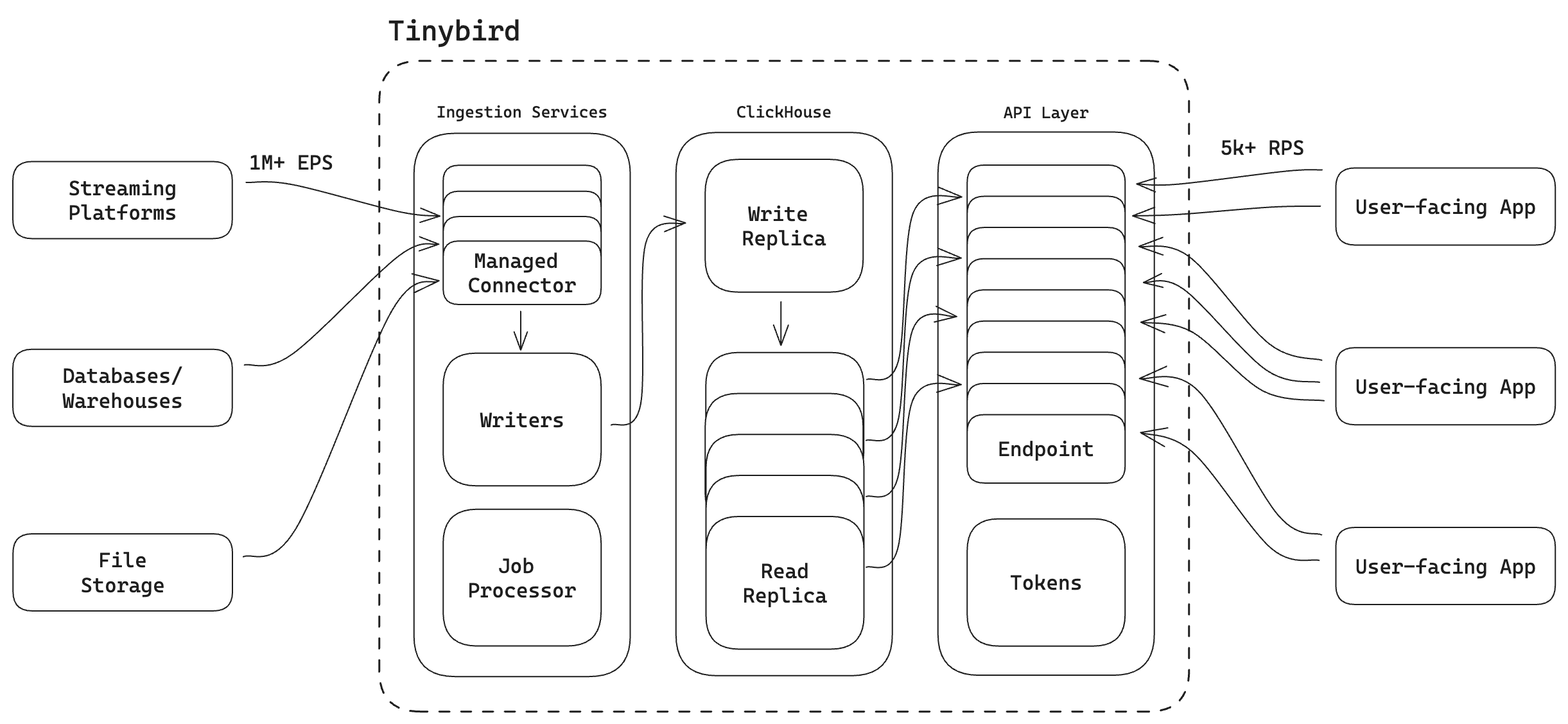
As you can see, the challenge presented by streaming data is that any change to the schema of a Data Source can have immediate and cascading effects all the way up to your user-facing product. When you're simultaneously streaming data and serving thousands of concurrent API requests, schema migrations become especially risky.
Schema migrations on tables with streaming ingestion present a significant risk, as any problems or mistakes can immediately cascade to the end user.
The anatomy of a streaming ClickHouse schema migration in Tinybird
At Tinybird, we maintain an internal observability data project that is deployed in every one of our supported regions (dozens of ClickHouse clusters).
Within that data project is a table called pipe_stats_rt. It stores a row for every request made against every Tinybird API for the last 7 days. It contains roughly 20 columns, including:
pipe_idprocessed_bytesresult_rowstoken_namestatus_codeduration- etc.
This table is one of our Service Data Sources, a set of tables for which every Tinybird customer has a partial view. Service Data Sources like pipe_stats_rt allow Tinybird to monitor and explore their Tinybird usage in real time using SQL queries that they can then publish as observability APIs.
Here, for example, is some SQL you could write over pipe_stats_rt to get the average processed data of an API over the last 60 minutes:
Like any Tinybird Pipe, this can be published as a parameterized API.
We needed to add a new column in pipe_stats_rt based on customer feedback
Recently, one of our largest customers came to us with a problem. They use Tinybird to build APIs and integrate them into user-facing products like their retail websites, mobile apps, etc.
The data engineers at this company use pipe_stats_rt to monitor these APIs for errors after they've been integrated into the software. If the frontend teams use an incorrect data type or improper formatting for a query parameter, for example, it will show up as an error in pipe_stats_rt.
Until recently, Tinybird didn't expose the user agent of the API request in pipe_stats_rt, which meant that our customer struggled to determine if errors were isolated to certain brands or applications. It would often take them a few days to figure out which team was actually responsible for improperly integrated APIs.
Since each website or application sent a unique user_agent, they asked us to add the user_agent request data to the Service Data Source so they could better isolate and debug API integration problems.
This, of course, called for a schema migration on the pipe_stats_rt table, which stores terabytes of data, ingests thousands of events per second, and is deployed across dozens of clusters supporting many concurrent user queries. 😳
How we approached the schema migration
When we work with customers, we often recommend that you don't maintain the critical schema in the table in which the raw usage events are written, especially when you have unstructured data sources that may add or subtract new fields at any point in time.
As a rule of thumb, it's a lot easier to migrate the schema of a Materialized View than a landing Data Source, and in most cases, the teams that manage the landing Data Source (typically Data Engineering) are often different from the teams developing APIs over Materialized Views (typically Software Engineering).
It is good practice to maintain the critical schema outside of the landing table. This way you can make changes downstream without breaking ingestion.
In our case, the landing Data Source in our internal project contains only a few columns, with the entire event payload stored in a single column as a JSON string.
We parse that JSON in an SQL Pipe and create a Materialized View from the results, defining the needed schema in the resulting Materialized View. It's this Materialized View with which our users can interact.
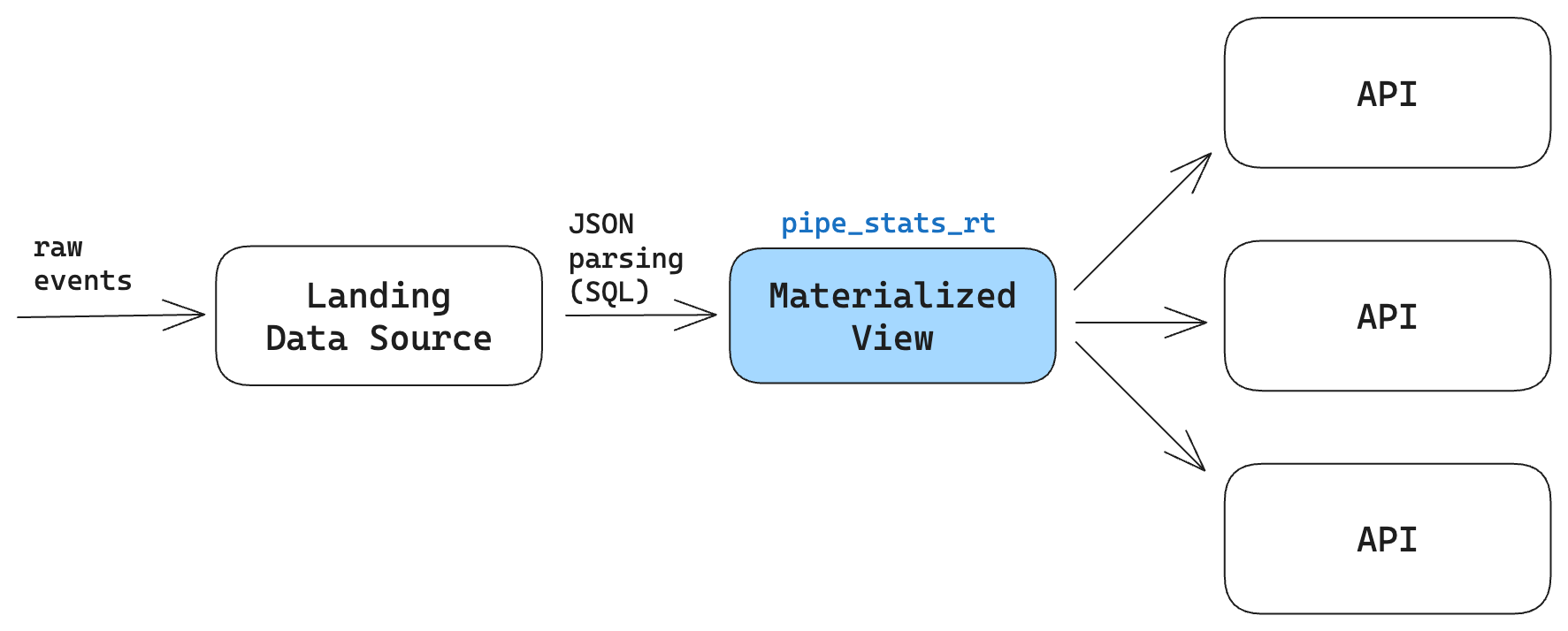
Because we define pipe_stats_rt in a Materialized View, we could make the change in our application backend to add the user_agent attribute to the JSON payload without requiring a schema change to the landing Data Source, and therefore without breaking ingestion. We could then modify the schema in the Materialized View even as new events with the user_agent attribute were streaming in.
But altering ClickHouse Materialized Views isn't very robust
Unfortunately, altering a Materialized View in ClickHouse is an experimental feature behind a feature flag. Even if you can do it, you generally don't want to. Making a hot change to a Materialized View that's constantly receiving update triggers from new rows in the landing Data Source can lead to all kinds of cascading issues that can be very hard to undo.
So, how do you avoid hot changes on a Materialized View that's getting triggered to update thousands of times a second?
Past: Use ClickHouse and a lot of manual operations
In the past, this was painful. It was manual, slow, and brittle. We had to directly interact with the underlying ClickHouse clusters and manually create and deploy all the new resources.
The basic steps looked like this:
- ssh into the production ClickHouse cluster
- Create a new table,
pipe_stats_rt_newin each cluster - Create a new ClickHouse materialized view to begin writing to the new table
- Make sure the new materialized view is actually being triggered by manually initiating a query
- Make an
INSERT INTO _ SELECTquery to backfill all the data, making sure not to leave gaps or duplicates. - Use a ClickHouse
EXCHANGEoperation to swap the old table for the new one while ensuring the operation is atomic. - Do each of these steps for every single region, with the added caveat that each cluster has slightly different requirements based on how it is configured.
This whole operation could take a week or more, and it wasn't getting any easier as we added more Enterprise customers in new cloud regions.
If we made a mistake, the effects could be catastrophic. We had an internal document with all the steps, quirks, and tribal knowledge needed to avoid breaking production.
We had an internal document with all the steps to follow, the various quirks and tribal knowledge, what to do in case of catastrophe, etc. Any mistake could result in broken production data pipelines, which ultimately meant data loss.
We did eventually automate part of this operation to make it less manual, but still we lacked any way of testing the change in an isolated environment. We couldn't run an automated test suite and thus had no safe way of deploying the changes to production.
We did what most data engineers do for schema migrations, etc.: run some random queries here and there a.k.a. "the eyeball test".
Present: Use version control
We recently released a git integration for Tinybird, offering some features on top of ClickHouse that make this kind of schema migration much less painful.
In this case, Tinybird can enable a fork downstream, When you create a new branch, Tinybird will analyze the dependency graph and apply changes to the updated Data Sources and all of the downstream dependencies in the new branch.
Using Tinybird's git integration, our schema migrations rely on tried and true software development principles like version control, CI/CD, and automated testing.
You can maintain these changes in Releases, so you can have a Live Release, which is in production, and a Preview Release, which you can use to test the changes in a production-like sandbox that contains an exact copy of the production resources, including the last partition of data.
This means you can test how schema changes propagate all the way into the application by utilizing the new Endpoints in your test branch, which will query real production data. When you're happy, you can merge and deploy the changes.
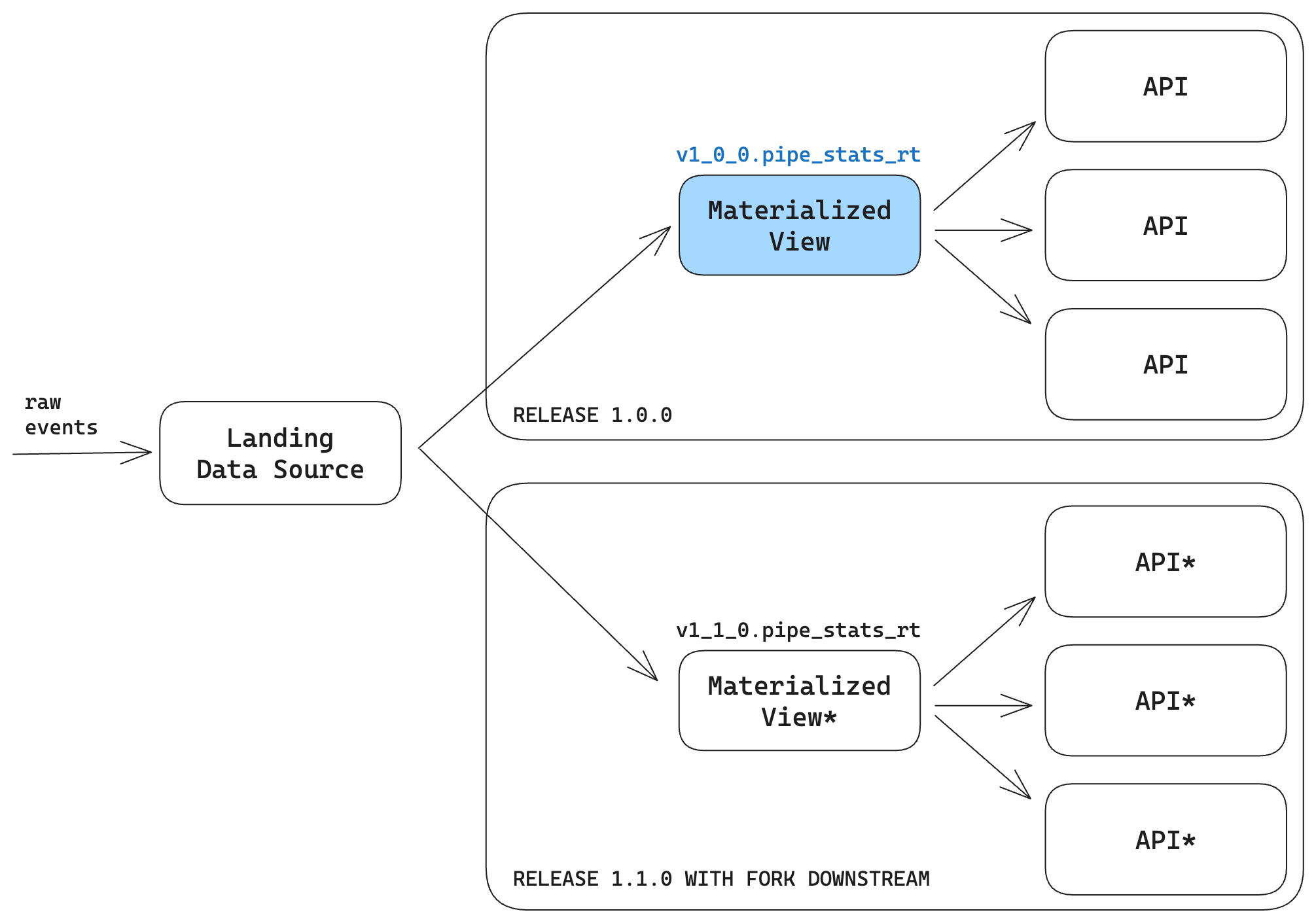
There are some other great features and benefits here:
- Rollbacks. If you mess something up, the old Materialized View still exists in the original branch, so it's easy to roll back to a previous state if needed.
- Backfilling with no data loss. Since you're maintaining the old downstream in production, it's easier to use Continuous Deployment actions to backfill all the historical data before the migration (without duplicating any of the data after).
- Previews. Since you have a copy of all the downstream dependencies, it's easy to evaluate performance and quality using production data before you merge the changes into production.
Of course, there is a drawback, namely that you have to maintain the data resources on both branches while you perform backfill operations. This results in duplicate data processing, but given the amount of time and pain it saves you, we think this is a more than acceptable tradeoff.
How we did the schema migration
We use Tinybird's integration with git to manage our Internal data project as we would any software project. The code is housed in a git repository synced to the Tinybird Workspace so that changes deployed in git are propagated to the Tinybird servers.
In our case, we host our code in GitLab, make changes to the data project files alongside the rest of our application code, and then use CI/CD pipelines in GitLab to safely merge and deploy the changes.
Since everything is defined in textfiles and maintained in source control, the process of making the schema change was just like any other process you'd follow in software version control:
- Create a new branch
- Make and commit the changes to the schema
- Create a merge request with the commits
- Write the script to perform the backfill during deployment
- Generate some data fixtures and write tests to ensure quality
- Deploy the changes to a CI branch to run the tests
- Review the CI
- Merge and deploy
In this case, the actual code change is simple. We just have to extract the user_agent from the tag column in the landing Data Source in the Pipe which generates our resulting Materialized View…
… and add the new column to the schema of the Materialized View:
Both of these changes were committed and pushed to the new branch.
Backfilling
To backfill data, we wrote a script that populated data since the new user_agent column started being ingested up until the current time when the script is run, and then we copied the rest of the historical data over to the new Materialized View.
To do this, we used parameterized Copy Pipes, another Tinybird feature that allows you to append the results of an SQL query into an existing (or new) Data Source.
Here, for example, is the .pipe file for the Copy Pipe that we used to populate empty user_agent data up until the new user_agent column was added:
When you deploy a Copy Pipe to Tinybird, a Copy Job is created that you can run on demand. In this case, we ran the job as a part of the deployment in both CI and CD. Since the copy operations are parameterized, we could pass the current time during CI/CD execution or leave the user_agent empty:
The above script ensured that we had all the historical data backfilled in both the CI branch and in production after the changes were merged and deployed. It guaranteed there were no duplicates or missing events in the final Materialized View.
In addition, because the Copy Pipes are parameterized, we could even batch the backfill operations by passing different DateTime parameters, so the backfill operations could scale based on the size of the table. In some regions with more load, we broke up the backfill jobs by day to avoid overloading the ClickHouse cluster.
Testing
After making the schema change and backfilling, we wanted to run some tests to make sure that the changes we got were the changes we expected, namely that new user_agent entries were being correctly materialized.
In a Tinybird data project, you implement testing strategies with .test files, such as those shown below, that contain some commands to run tests over data fixtures supplied during the CI/CD:
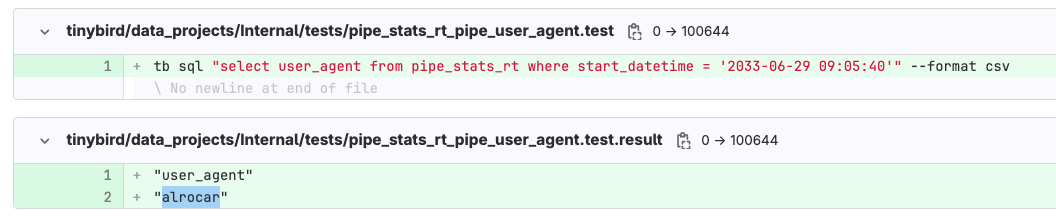
user_agent in the Materialized View.In addition to these automated tests, the CI branch is deployed to the Tinybird server, so you can double-check the changes in Preview to do some manual data quality checks or peer reviewing using Playgrounds.
Deploying to 20+ regions
Once the Merge Request had been deployed and tested in CI, the final step was to deploy the changes in production across all of the different regions and ClickHouse clusters.
The process was exactly the same as deploying to the CI branch, but with a different set of credentials for each region's Internal Workspace:
Promote to Live
As I mentioned earlier, Tinybird manages versioned deployments through Releases. After CD, the changes merged into your production git branch are reflected in a Preview Release in Tinybird. Therefore, the last thing we did was promote the Preview Release with our changes to the Live Release, thus syncing the Tinybird servers to the production code branch and completing the schema migration!
8/100 #100DaysOfCode 👨💻
— alrocar 🥘 (@alrocar) February 5, 2024
Desde la semana pasada, los usuarios de Tinybird pueden obtener métricas de las APIs que publican filtrando o agrupando por "user_agent" pic.twitter.com/SWtLMpeTbT
Summary and resources
Schema migrations are never easy. But doing it in a production streaming data system is much, much harder because of all the moving pieces, the data operations required, and the end-to-end nature of the project.
And, unfortunately, these operations don't natively exist in ClickHouse, because really it's more of a data engineering problem than a database problem. It requires careful data operations and code management.
These operations don't exist in ClickHouse. Which makes sense, because it's not a database problem. It's a data engineering problem.
Tinybird's git integration was a friend here, and it allowed us to manage and iterate our internal data project alongside the same code we had written to build the user-facing product itself. This made it relatively painless for us to support our customer and reduce their debug time from days to seconds.
Generally speaking, by integrating Tinybird with git, we can rely on tried and tested software principles that make streaming schema migrations much easier and safer.
If you'd like to learn more about some of these principles and how they guide work in Tinybird, check out our documentation on version control with real-time data projects.
You can also read up on Materialized Views and how they work in Tinybird.
If you have any questions about this work and how we implemented it, we'd love to chat. You can message us in our public Slack community.