Dynamic API reponses based on endpoint parameters
Make your Tinybird real-time API endpoints to return data at different resolutions depending on the selected temporal range.


Capturing large amounts of data is the new normal. These days, it is not uncommon to have datasets with a per-second resolution for a few years worth of data. While this poses some demands at the storage and the query layers, it also presents some challenges for the data consumers:
- Client-side rendering: modern web browsers are very capable, but transferring large quantities of data can become slow depending on the bandwidth and can swamp the rendering performance.
- Working with Excel or Google Spreadsheets: analyzing raw data might halt your application or make your analysis unusable.
- Privacy: when you have to preserve the confidentially, returning raw data is not always an option. You might want to return good-enough granularity without exposing raw events.
In this post, we focus on the first challenge: we will render a candlestick chart.
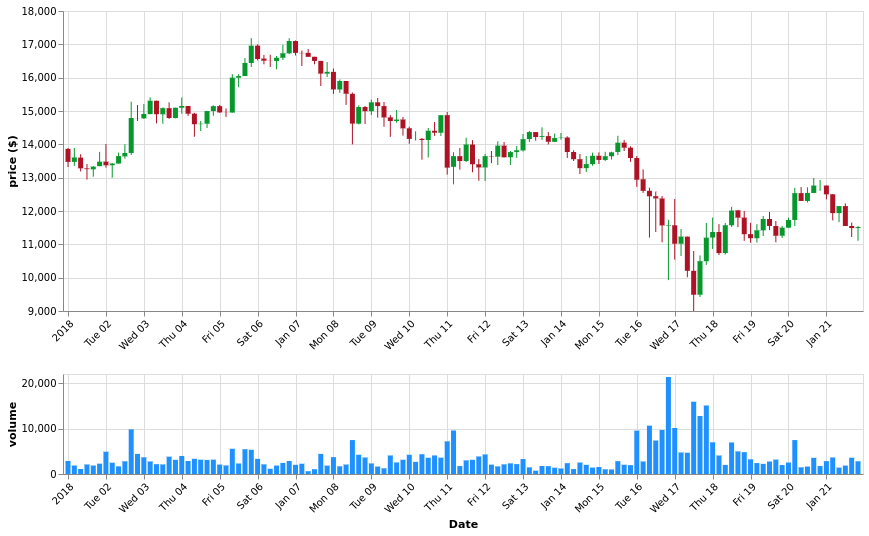
We will create an API endpoint that returns OHLC data and the trading volume for a random time range. To use a dataset with enough granularity and a big enough interval, we will use the Coinbase's BTC/USD pair as found in the Bitcoincharts' Markets API. The coinbaseUSD.csv contains ~56M transactions for a ~4 years span.
We want to render our candlestick graph for any date range. That way, we can get the whole picture but also drill down into the details. We also want keep our API endpoint interface simple: "I want OHLC data from this start date to this end date" simple.
This way, we separate two concerns:
- When working on the API endpoint, you can focus on returning enough data with adequate resolution for the selected date range.
- When working on the visualization, you don't have to worry about how to do the aggregation of the returned data: you simply request the desired date range knowing that you will receive an amount of data that won't swamp your rendering pipeline.
Building our dynamic API endpoint
First, we need to get our dataset into Tinybird. As per Bitcoincharts documentation, the CSV files have the following columns: unixtime, price, and amount. As we want to work with a more manageable type for the unixtime column, when creating our Data Source, we are going to define a materialized column that, at ingest time, transforms our unixtime integer into a DateTime column:
We create the coinbase_btcusd empty Data Source using the schema parameter:
We are ready to ingest our dataset, so we just issue a request to the Data Sources API with the URL.
After doing some basic exploration, we know how our dataset looks like and how we will expose the OHLC and volume data in our API endpoint. Depending on the number of days in the date range, we will change the interval by which we aggregate. This way, we constrain the number of returned rows: reducing the data transferred and alleviating the rendering pipeline in the client-side.
We create the btcusd_ohlcv Pipe with a node with the following query:
Let's review some of the details of our query:
- We have a couple of parameters:
{{Date(start_date, '2018-01-01')}}and{{Date(end_date, '2018-12-31')}}. We define them asDateparameters, with some default values for the start date and the end date. - We compute the number of days in the interval defined by those
start_dateand theend_dateparameters:days_interval = day_diff(...). - We use that
days_intervalvariable to decide what date granularity we want to use, using some basic logic operators. - We take advantage of the argMin and argMax aggregate functions to compute the open and close figures for the range.
After creating the Pipe, we enable our node as the endpoint.
We can already test our API endpoint:
Consuming data from a candlestick chart
Taking this Vega-Lite's candlestick example as inspiration, we have built a simple dashboard with date pickers and the chart that consumes data from our OHLCV API endpoint.
Conclusion
With Tinybird, you can dynamically return different responses from your analytics API endpoints depending on the request's parameters. This can give you a more granular control over the data you send to the client, either for performance or for privacy reasons.