Simple patterns for aggregating on DynamoDB
DynamoDB doesn't natively support aggregations, so here are four different approaches to aggregate data in DynamoDB tables.


DynamoDB is a fast and scalable NoSQL key-value store used by millions of developers worldwide who are building real-time applications. When you use DynamoDB, you come to expect read/write operations that run in milliseconds. Yes, it's that fast for transactional use cases. And it remains that fast even at an absurd scale. That's why it's awesome.
But DynamoDB is purely a transactional database. It maintains consistent performance at massive scale so long as your access patterns involve point lookups and small-range scans using the primary key.
Aggregations are a different access pattern. In DynamoDB, they generally involve a full scan of all items. This is an expensive and slow operation.
So what do you do if you want to run aggregations on data in DynamoDB? Here are a few simple patterns for aggregating DynamoDB data. Each of these patterns has various benefits and tradeoffs, as you'll see, but they all satisfy the core requirement to run aggregations over DynamoDB data in a relatively performant and cost-effective manner.
Pattern 1: Aggregate in batch with Redshift
Since DynamoDB does not natively support aggregation patterns, you have to move the data outside of DynamoDB to perform aggregations.
If you don't need your aggregations to be calculated in real time, you can offload your tables to another data tool optimized for online analytics processing (OLAP) workloads, such as Amazon Redshift.
Amazon Redshift provides the classic data warehouse experience: scalability, storage/compute separation, and an SQL interface for querying. This makes it suitable for large-scale analytics workloads to power business intelligence interfaces.
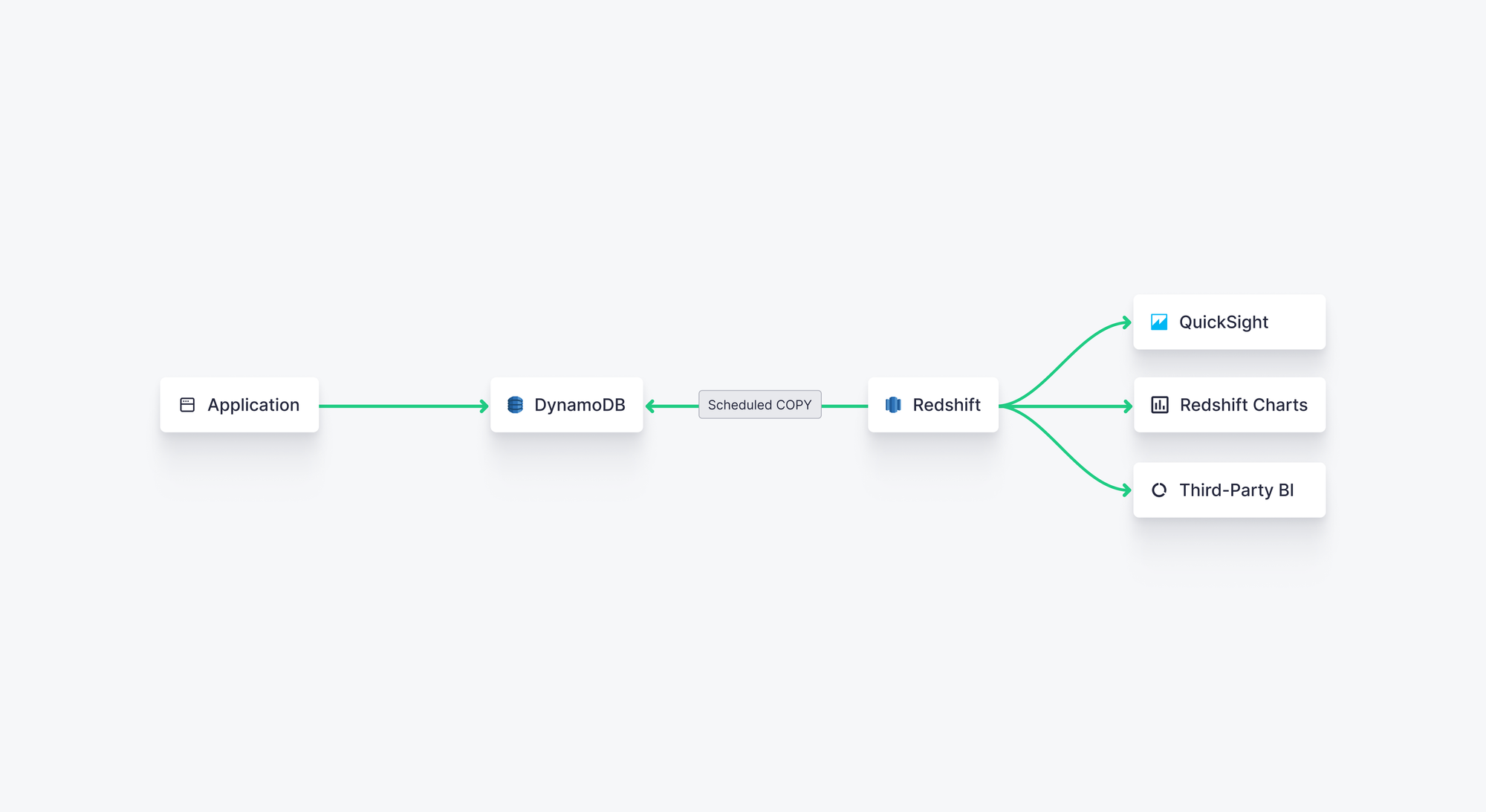
COPY command to copy data from DynamoDB to Redshift, which you can then integrate with downstream Business Intelligence (BI) tools for ad hoc querying, reporting, and dashboarding.To get data from DynamoDB into Redshift, you can use the COPY SQL command in Redshift to copy data from your DynamoDB table into Redshift, for example:
Pros
- Redshift is well-suited for large-scale analytical processing that involves aggregations
- Redshift is highly scalable for these types of workloads
- Redshift presents an intuitive SQL interface
- Redshift integrates easily with DynamoDB using the
COPYcommand - Redshift can be deployed serverless for simplicity at scale
Cons
- The
COPYcommand only copies a current snapshot of the DynamoDB table, so it will need to be periodically refreshed depending on the downstream analytics use case - The
COPYcommand consumes DynamoDB read capacity units, which adds cost and can impact performance on your DynamoDB table - Because the
COPYcommand consumes provisioned throughput on your DynamoDB table, AWS recommends against using it on production tables or setting thereadratioto a value lower than the minimum available capacity on DynamoDB, which creates a speed/cost tradeoff. - Copying data from a NoSQL environment to an SQL environment creates some trickiness, as you need to account for differences in data types, treatment of
NULLvalues, etc. - Redshift is not suited for real-time analytics, so this approach should not be used when analytical queries must run with low latency or high concurrency (typically required in applications where DynamoDB is used).
TL;DR
You can use Amazon Redshift to perform scheduled COPY operations of DynamoDB tables for batch analytical workloads. This is a decent approach for business intelligence or internal reporting use cases but unsuited for real-time or user-facing analytics.
More resources
Pattern 2: Aggregate in batch with Apache Hive on EMR
This approach is similar in form to that described above, except using Apache Hive instead of Redshift as a destination for DynamoDB tables.
Running Apache Hive on EMR is like running Postgres on EC2 - you get the benefits of an open source tech backed by Amazon's scalability. Apache Hive presents an SQL-like interface (called HiveQL) that ultimately invokes MapReduce functions to perform aggregations, giving you quite a bit of flexibility for running complex analytical processes over massively distributed datasets.
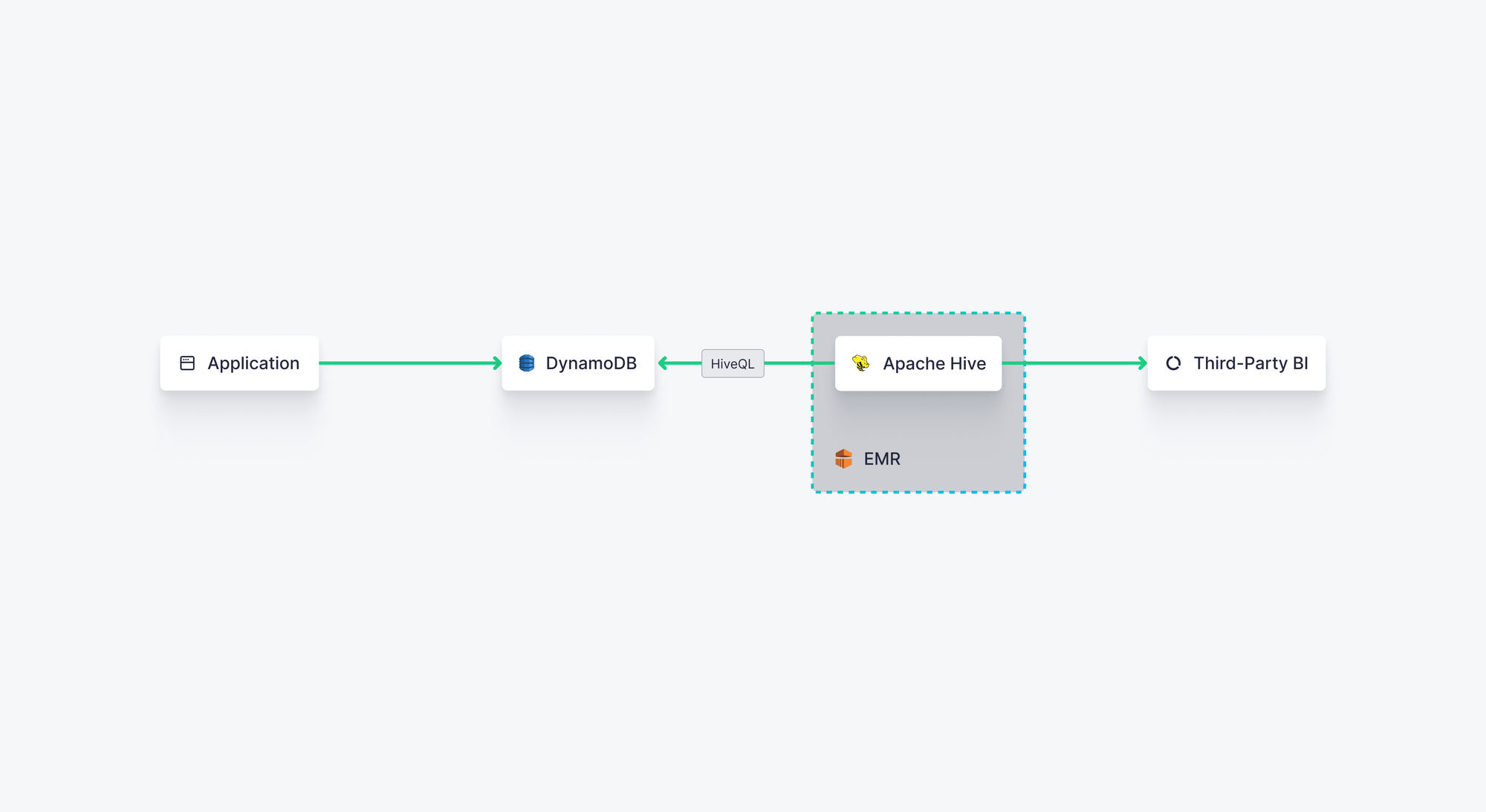
Getting data from DynamoDB to Apache Hive can be a bit complex, however, requiring you to set up an EMR cluster, SSH into the leader node, and manually set up the Hive table (with a pre-defined schema) to align with your DynamoDB table. This can get a bit tricky when dealing with single-table designs in DynamoDB, but you'll have difficulty moving data from DynamoDB to any schema-dependent data structure.
You can follow this step-by-step tutorial to learn how to copy data from DynamoDB to Hive. The basic steps are:
- Create an EMR cluster
- Connect to the leader node
- Set up the Hive table based on a pre-defined schema
- Link the Hive table to the DynamoDB table
- Query the DynamoDB table using HiveQL
Pros
- You get the benefits of open source tech (Apache Hive) on scalable AWS clusters (EMR).
- Apache Hive presents an SQL-like interface that can be familiar to analysts and data engineers
- Apache Hive can handle query processing on massive, distributed datasets
- As with the prior approach, fetching data from DynamoDB when querying will consume read capacity units.
Cons
- Setting up an EMR cluster can be complex and costly
- Apache Hive is not suited for real-time data processing, so this approach only works for batch
- AWS doesn't have any native integrations for visualizing or otherwise integrating the results of Hive queries into another tool, so this is really only useful for ad hoc querying
TL;DR
If you want to run complex, ad hoc analytics queries on DynamoDB data and you're familiar with the Hadoop ecosystem, copying your DynamoDB data to Apache Hive will give you a scalable and flexible system to query your data, but it won't work for real-time processing needs or when you want to integrate the results of your queries back into a user-facing application or dashboard.
More resources
Pattern 3: Aggregate to a separate DynamoDB table or GSI with AWS Lambda
DynamoDB is typically selected to back user-facing applications with real-time needs: low latency and high concurrency on both reads and writes. If your goal is to surface aggregations in the same application, you can find some efficiency by just putting those aggregations back into DynamoDB. You're already working with the database, so why not keep working with it?
To do this, you need to enable DynamoDB Streams on your DynamoDB table, which will produce CDC-style streams as new updates are inserted into your DynamoDB table. Then, you can use an AWS Lambda triggered by these streams to calculate aggregates and store them in a separate DynamoDB table. Your Lambda can also read from your aggregates target table to fetch existing aggregates and update them based on new data.
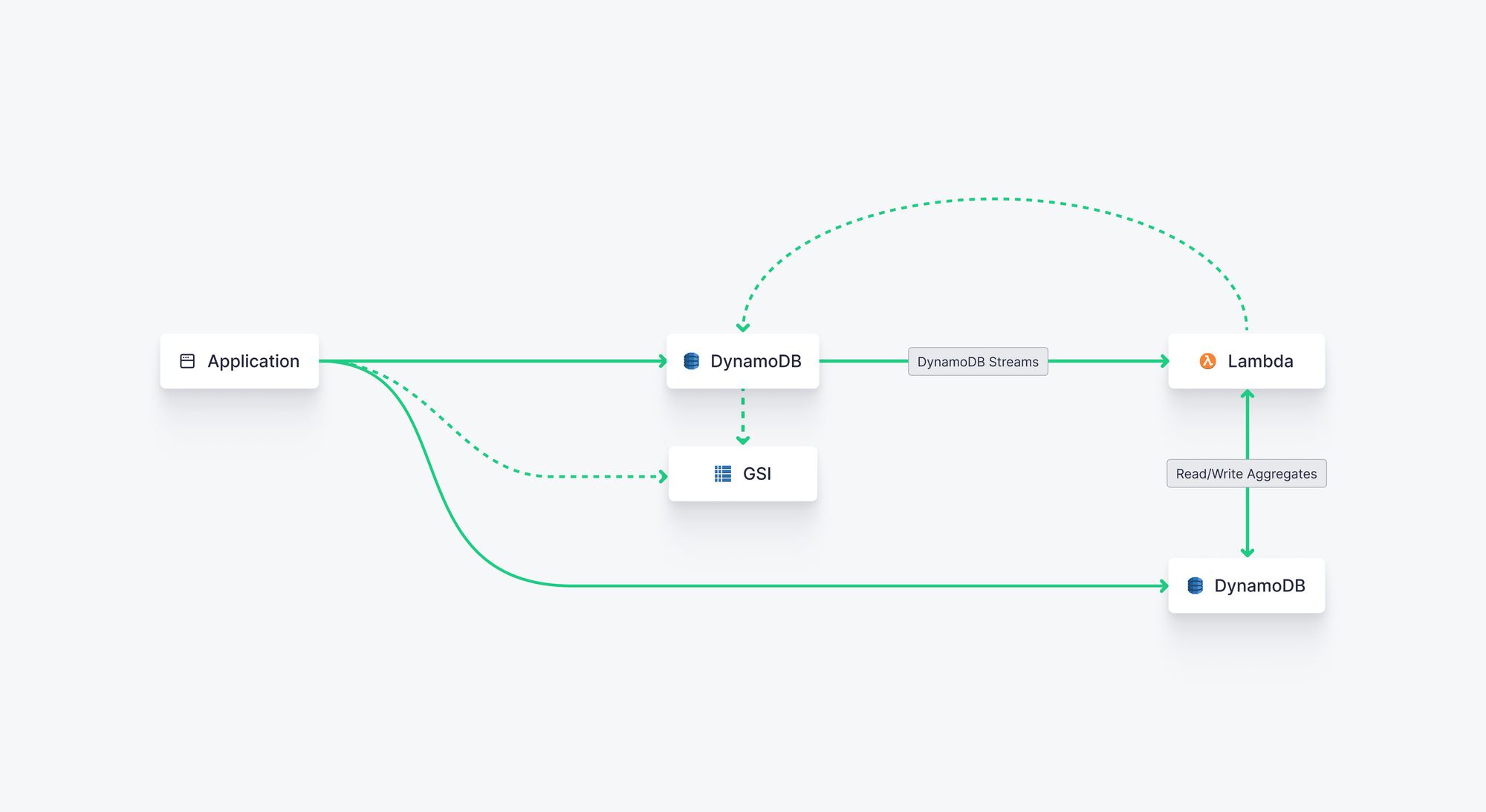
Amazon has a good tutorial for this workflow here. The basic steps are:
- Enable DynamoDB streams on your DynamoDB source table
- Create a DynamoDB target table to store your aggregates
- Create a Lambda function with roles to read/write from the DynamoDB tables
- Set up triggers for the Lambda based on DynamoDB Stream output
- The Lambda then runs as filters are met, writing aggregates to the target table
Pros
- You can continue to use DynamoDB to store aggregates, so you stick with a familiar interface.
- This approach works for real-time applications. If your Lambda function is efficient and properly scaled, you can achieve sub-second end-to-end latencies to write and read aggregates.
- Reading aggregates is fast because they're properly indexed in your DynamoDB target table or Global Secondary Index (GSI)
- Leverages existing DynamoDB functionality (Streams).
- Lambda read requests (4 times per second) to the DynamoDB Stream are free.
- Doesn't consume read capacity units from your source table, so this can effectively be used in production without straining your app database.
Cons
- This approach offers very little flexibility. Aggregates are pre-computed and indexed by a primary key, so you won't be able to dynamically filter on the read side.
- While read requests by Lambda to DynamoDB Streams are free, Lambda invocations aren't. Those costs can creep up if you're invoking the Lambda function many times per second.
- Lambda is doing a lot of work here. If it fails, your aggregates could be inaccurate, which won't work in an environment where you need strong consistency.
TL;DR
Using a Lambda to calculate aggregates and write them to another DynamoDB table is a solid approach when you need near-real-time aggregates that you can surface in your application, but this approach won't offer the same query flexibility as prior approaches.
More resources
- 3 ways to run real-time analytics on AWS with DynamoDB
- Build aggregations for Amazon DynamoDB tables using Amazon DynamoDB Streams
- Using Global Secondary Indexes for materialized aggregation queries in DynamoDB
Pattern 4: Aggregate in real-time using Tinybird as a secondary index
Tinybird is a real-time data platform that runs on AWS. It's built on open source ClickHouse® and is optimized for low-latency, high-concurrency reads and writes for OLAP workloads. It offers a native DynamoDB Connector, gives you the ability to query DynamoDB tables with SQL, and features an "instant API" experience to publish query results as scalable REST API Endpoints that integrate with your app.
In this approach, you effectively use Tinybird as a secondary index of your DynamoDB table, but with a data structure that supports complex aggregates (plus filters and joins) at low read latencies similar to what you can achieve with DynamoDB. You can also add dynamic logic to your SQL, allowing you to pass query parameters to your aggregating functions for tremendous flexibility.
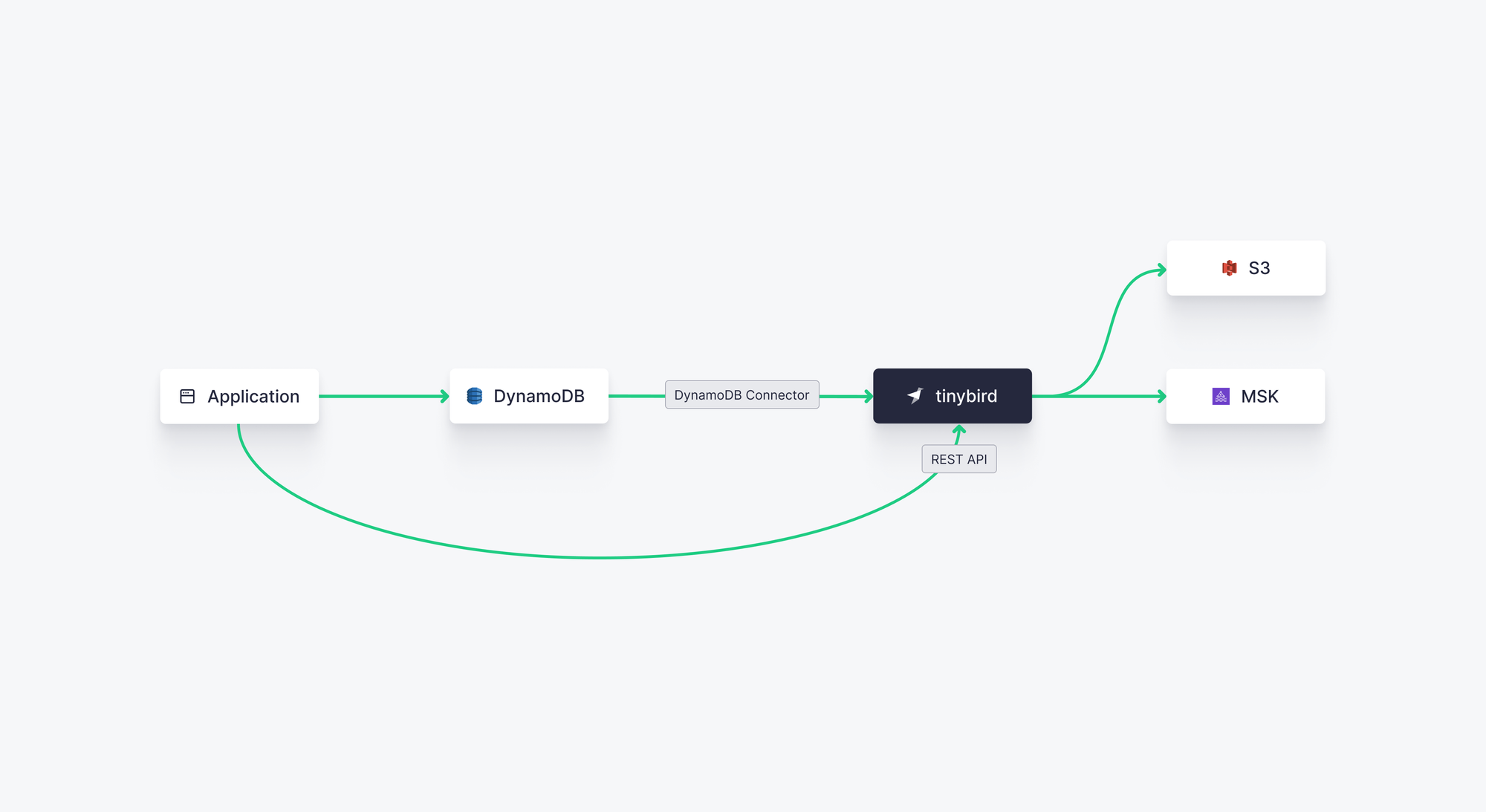
To connect DynamoDB to Tinybird, you can use Tinybird's native DynamoDB Connector, which uses Point-in-Time Recovery (PITR) to automatically create an initial snapshot of the DynamoDB table, then uses DynamoDB Streams to consume CDC upserts and deduplicate them. The process ensures a consistent, stateful copy of your DynamoDB table with only a few seconds of latency.
Once your DynamoDB data is in Tinybird, you can write SQL queries to filter, aggregate, and join. Every query can be published as a scalable, low-latency REST API Endpoint secured by custom JWTs, so integrating real-time analytics into your application is simple.
Pros
- Tinybird combines the low-latency/high-concurrency benefits of DynamoDB with the query flexibility and analytics capabilities of tools like Redshift and Hive.
- Tinybird has a native DynamoDB Connector to maintain a stateful copy of DynamoDB tables without needing to write or maintain any external ETLs.
- You can publish aggregating queries as hosted, scalable REST API Endpoints with dynamic query parameters, which makes for easy integration with user-facing apps.
- Tinybird supports handling JSON and semi-structured data.
- Tinybird is available on AWS and can be purchased through the AWS Marketplace.
Cons
- Tinybird is a managed service that, for now, can't be self-hosted on your own AWS cloud. Tinybird does, however, maintain a "Bring your Own Cloud" waitlist for those interested in self-hosting in the future.
- Like Redshift and Hive, Tinybird uses table schemas for indexing, which can be uncomfortable for developers familiar with the schemaless approach of DynamoDB.
- Because of its schema pattern, using Tinybird in conjunction with single-table designs in DynamoDB can add some complexity, requiring you to parse raw data into multiple target tables using Materialized Views.
TL;DR
When you need the flexibility of dynamic aggregations with real-time processing performance, Tinybird pairs perfectly with DynamoDB. Its native DynamoDB Connector simplifies integration with DynamoDB, and its hosted, scalable API Endpoints simplify integrating dynamic aggregate queries back into your application.
More resources
Wrap up
DynamoDB doesn't natively support aggregation functionality, but you can extend it to achieve aggregations with any of these 4 approaches. Each approach ranges in its use cases, from batch to real-time, and its flexibility, performance, and cost.
If you need flexible, ad hoc querying in batch, you can use Redshift or Hive. If you need real-time performance without dynamic flexibility, you can simply reuse DynamoDB. If you need both real-time performance and flexibility to dynamically calculate aggregates, Tinybird is the way to go.
Here's a table summarizing the pros and cons of each approach.
| Approach | Pros | Cons |
|---|---|---|
| Amazon Redshift |
|
|
| Apache Hive + EMR |
|
|
| AWS Lambda + DynamoDB |
|
|
| Tinybird |
|
|
Tinybird is free to use. The Build Plan has no time limit, no credit card required, and plenty of capacity to prove your DynamoDB aggregation use case. You can sign up for Tinybird here. If you have questions or get stuck, the Tinybird Slack Community is a great place to get answers.
ClickHouse®️ is a registered trademark of ClickHouse, Inc.