Top Use Cases for DynamoDB in 2024
DynamoDB… it's fast, scalable, and flexible. What's not to love? Here are the top use cases for DynamoDB in 2024 (and a few areas where it won't work).


Amazon's DynamoDB is a fast, NoSQL key-value database widely adopted by engineering teams who need a real-time, distributed data storage solution within the AWS ecosystem.
DynamoDB is known for its impressive read/write performance even at extreme scale, and it's backed by all of the benefits that come with the surrounding AWS ecosystem, including high availability, on-demand scaling, fault tolerance, multi-region replication, and tight integration with other AWS services like Lambda, S3, IAM, etc.
As a distributed NoSQL database, DynamoDB can scale even under extreme load. Workloads that might bring down even the most heavily sharded RDBMSs can run just fine on DynamoDB thanks to its horizontal scalability and partition management.
Put simply, it's a great database when you need to write and retrieve data very quickly, which is true for almost every modern web application. Hence the popularity of DynamoDB!
Let's look at some common use cases for DynamoDB, assessing its strengths along the way. We'll also highlight some areas where DynamoDB is not the right database, and offer some alternatives when DynamoDB just isn't it.
What are DynamoDB's strengths?
DynamoDB is a rock-solid database at scale. It's tremendously fast for key-value writes and reads. It benefits from massive scalability backed by AWS, has an efficient and automatic caching layer, and offers a lot of flexibility thanks to its schemaless data model.
Here's what makes DynamoDB great:
Serverless architecture
Want a fast database without managing the infrastructure yourself? If you're already working on AWS, then DynamoDB offers just that. Unlike a self-hosted, open source database, DynamoDB gives you the benefits of a managed, serverless setup: predictable pricing, reduced development costs, autoscaling, automatic upgrades, fault tolerance, and tight integration within the AWS ecosystem.
Sure, some folks like to self-host OSS, but if you (or your client) are already working with AWS tools, it's hard to argue against DynamoDB.
Schemaless flexibility
As a distributed NoSQL database similar to popular databases like MongoDB and Apache Cassandra, DynamoDB benefits from its schemaless architecture. You set a primary key to define how data gets partitioned and, optionally, define a sort key; otherwise, you don't need to predefine table schemas.
The flexibility associated with a schemaless design makes it ideal for developers who frequently iterate their data models and need a database that can handle unstructured or semi-structured data. DynamoDB can do this without needing nullable columns or storing nested JSON objects as long strings in a single column, for example.
Low-latency writes
DynamoDB uses a Log-structured Merge (LSM) tree, a highly efficient data structure for writes. LSM trees are optimized for high throughput and efficient storage on disk by relying on in-memory structures to buffer writes. This makes it flexible and efficient even when incoming traffic is "bursty".
You can learn more about Log-structured Merge tree in this excellent article by the folks at ScyllaDB.
Low-latency key-value reads
DynamoDB is highly optimized for fast reads on key-value lookups, often minimizing read latencies to single-digit milliseconds. DynamoDB can further improve read latency to sub-milliseconds with DynamoDB Accelerator (DAX), an automatically managed cache that keeps frequently accessed data in memory for exceptionally fast lookups.
As with other NoSQL databases, DynamoDB benefits from its denormalized data model, which is easily replicated across clusters. This results in massively parallel processing for reads to maintains fast performance even under very intense workloads.
Additionally, DynamoDB allows for both eventually consistent and strongly consistent read access. If speed is more important than accuracy, you can use an eventually consistent read pattern. If accuracy is more important, you can specify strong consistency in your API requests.
You can learn more about this in Alex DeBrie's thorough article on eventual consistency in DynamoDB.
Load balancing using partitions
DynamoDB uses a hashed partition key to distribute data across multiple nodes. This ensures that read operations can be parallelized across multiple physical servers, which balances the load and ensures that no single server becomes a bottleneck.
Additionally, DynamoDB can shift read and write operations to hot partitions to automatically manage capacity across servers. By dynamically allocating resources to partitions experiencing the highest demand, DynamoDB can respond to uneven workloads and keep read performance fast.
High availability and scalability
DynamoDB is backed by the availability and scalability of AWS, the world's largest cloud. DynamoDB global tables automatically replicate data across multiple availability zones, which reduces latency by serving requests from the nearest zone and ensures seamless failover in the event of a regional outage.
And thanks to AWS, DynamoDB will scale on demand. You can get granular with provisioned capacity, and DynamoDB auto-scaling can adjust as necessary to scale throughput on partitions based on the demands of your application.
Top 5 Use Cases for DynamoDB in 2024
These are the five of the best use cases for DynamoDB in 2024:
- Gaming. Gaming often involves highly concurrent read and write patterns, especially in the case of massively multiplayer online gaming where many thousands or millions of players may access gaming servers simultaneously. The server must be able to handle read and write requests from globally distributed gamers in real time.
DynamoDB is well-suited for this use case because it easily scales across many global regions while still keeping read and write latency in single-digit milliseconds.
Companies like Capcom, PennyPop, and Electronic Arts have used DynamoDB to scale gaming applications. You can learn more about gaming use cases and design patterns for DynamoDB. - Content Streaming. Content streaming applications must be highly available and scalable and must utilize multi-AZ deployments to serve global audiences. Content streaming is also subject to uneven or bursty traffic (anybody else waiting for the next season of Severance??), so these applications also benefit from serverless compute models that scale based on demand.
DynamoDB can be a great application database for content streaming applications because of its ability to provide global replication of data across regions and a flexible load balancing to account for changes in viewership.
Companies like Netflix, Hulu, and Disney use DynamoDB to support their content streaming applications. - Banking and Finance. Financial transactions happen in real time, and mobile apps are now the standard user experience for banking. Customers expect to be able to manage their money from their phones and do so in real time. Banks need to be able to process many concurrent, global requests from banking customers and keep financial transactions both secure and up to date.
DynamoDB works for banking because it can handle the global scale and the fast read/write patterns needed to keep financial information up to date both at the server and in the user-facing application, and because it offers strongly consistent reads even on a distributed architecture, both banks and customers have assurance that their financial data is accurate and up to date.
Companies like Capital One, RobinHood, and PayPay use DynamoDB to reduce latency for their mobile apps. - Mobile and Web Apps. Across many industries, including those above, web and mobile apps serve many concurrent users in real time.
For all of the reasons described here, DynamoDB is a perfect database to back web and mobile apps built within the AWS ecosystem. It can scale to handle fluctuating traffic and offers the flexibility to maximize throughput without huge costs.
Companies like Duolingo, AirBnB, and Tinder use DynamoDB to build fast and scalable web and mobile applications. - Internet of Things. IoT use cases involve high-frequency writes and unpredictable throughput, as globally distributed devices create real-time data streams.
While DynamoDB isn't strictly a time series database, it can be used effectively for IoT applications, especially when paired with other AWS tools like IoT Core, Lambda, and Kinesis.
Companies like BMW, GE, and Verizon use DynamoDB to process IoT data.
How much does DynamoDB cost?
Amazon DynamoDB's pricing model is designed to be flexible. You can choose between a few different pricing options based on what you need. Want to optimize costs by pre-provisioning capacity? You can do that. Rather have a pure usage-based pricing model? That's also an option.
DynamoDB pricing can be broken down into several key components:
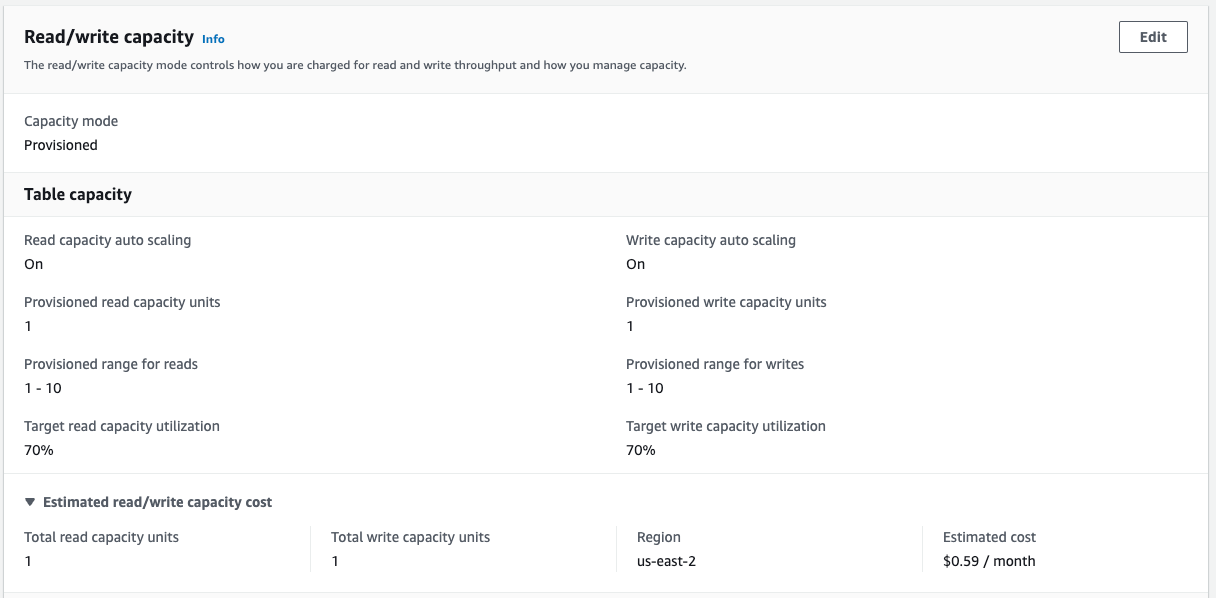
Provisioned Capacity Mode
In DynamoDB's Provisioned Capacity mode, you specify the number of read and write capacity units (RCUs and WCUs) that you need for your DynamoDB table. Your bill depends on the provisioned capacity regardless of usage.
In this pricing model, a Read Capacity Units (RCU) is defined as one strongly consistent read per second or two eventually consistent reads per second for items up to 4 KB in size. If your items are larger, you’ll need more RCUs. Similarly, Write Capacity Units (WCUs) are defined as one write per second for items up to 1 KB in size. Larger items require more WCUs.
Of course, this pricing model still benefits from autoscaling, so even if you've over- or under-provisioned, DynamoDB can adjust to handle capacity.
On-Demand Capacity Mode
In On-Demand Capacity mode, you don't need to specify read and write capacity upfront. Instead, you are charged based on the quantity of read and write requests made by your app. This is a pure usage-based model that allows you to avoid thinking about provisioning. This can also be useful when your traffic or access patterns are sporadic, "spiky", or otherwise unpredictable.
Here's a good explainer from AWS on Provisioned Capacity Mode vs. On-Demand Capacity Mode.
In addition to your preferred billing option, you'll also pay for things like data storage (including backups), data transfer costs (either to external clouds/services or different AWS regions), replication to global tables, the number of DynamoDB Accelerator (DAX) nodes you have provisioned, read/write operations for DyanmoDB Streams, and any reserved capacity you want to maintain for long term workloads.
Note that, like many AWS services, DynamoDB does have a free tier! The free tier follows the "rule of 25": 25 RCUs, 25 WCUs, and 25 GB of data storage per month. This is ideal for small or development workloads.
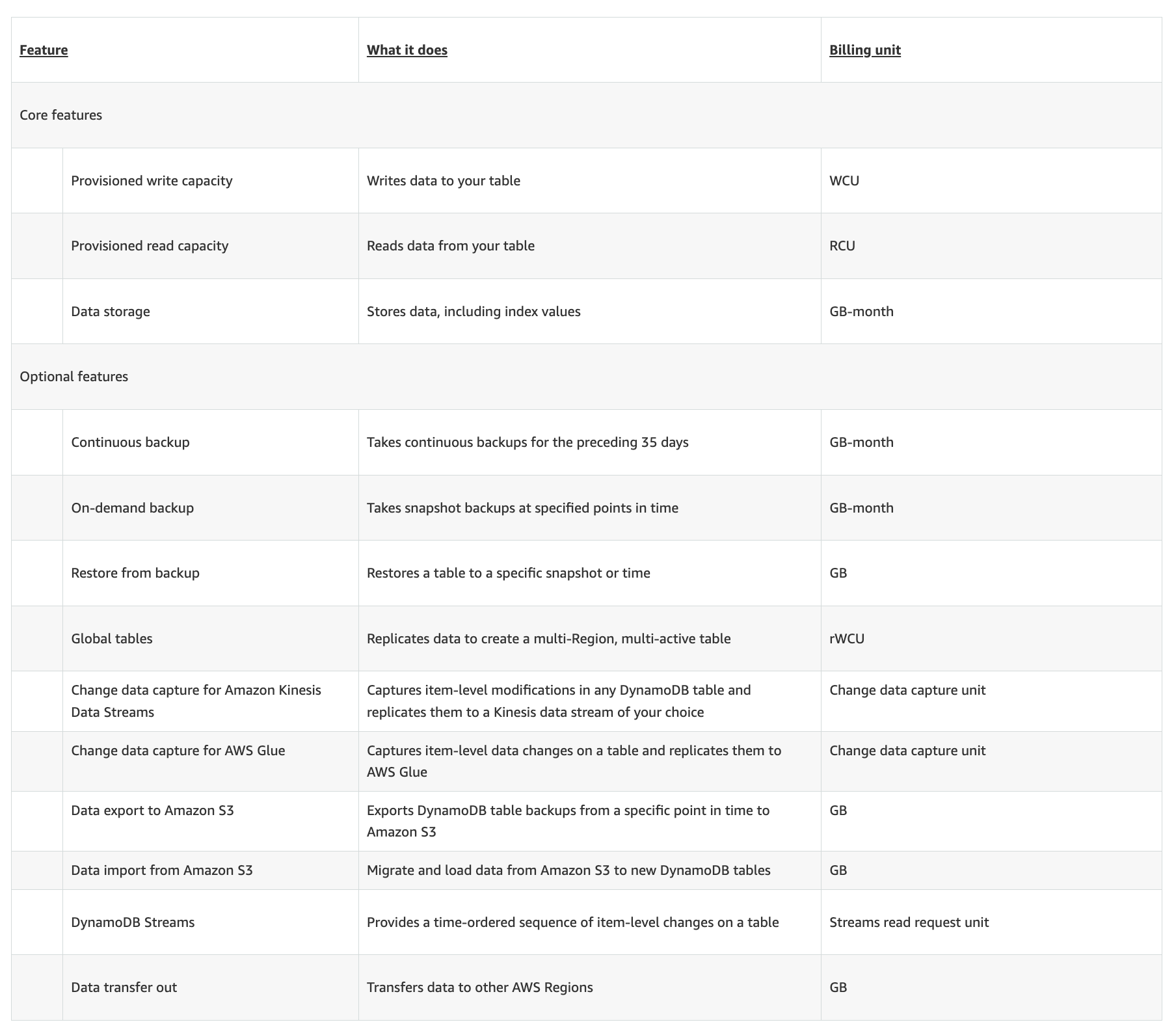
Example Cost Calculation for DynamoDB
Consider a relatively modest DynamoDB table with the following operational characteristics:
- Provisioned Mode: 100 RCUs and 50 WCUs
- Data Storage: 50 GB
- On-Demand Backup: 10 GB of backup data
- Data Transfer: 1 GB of data transferred out to the internet
- DAX: 1 x dax.t3.small node
In AWS's us-east region, your approximate monthly cost would be:
- $2.50/mo for 100 Provisioned RCUs (annual paid upfront)
- $6.25/mo for 50 Provisioned WCUs (annual paid upfront)
- $6.25/mo for 25 GB Storage (The first 25 GB is free)
- $2/mo for 10 GB Backup Storage
- $10/mo for 1 DAX node (assuming 8 hours active/day)
- $0.09/mo for 1 GB Data Transfer Out
- $27.09/mo total
Not bad! You can calculate DynamoDB costs with AWS's DynamoDB pricing calculator.
What are DynamoDB's weaknesses?
If this post hasn't made it abundantly clear, allow me to say it directly: DynamoDB is a fantastic database for many different use cases. It's fast, scalable, serverless, and flexible. It's most things you want in a database.
That said, like any tech, it can't serve every use case. Here are a few of DynamoDB's weaknesses, and some alternatives to fill the gaps.
Online Analytical Processing (OLAP)
DynamoDB is designed for very fast reads and writes for point lookups and small-range scans within a partition.
It's a key-value storage solution, so it's great if you need a value and have a key. But, if you need to compute aggregate values across many items, it can become very slow, very quickly.
DynamoDB is not built for analytical processing, which generally involves wide scans and filtered aggregations across many partitions. Using DynamoDB for analytical use cases will be horribly cost-inefficient because you'll have to provision a ton of capacity or pay for on-demand scaling for DynamoDB to access all the items needed to perform the aggregation.
Complex data modeling and lack of SQL support
DynamoDB is a NoSQL database. Many developers love NoSQL. Rather than use SQL to query and retrieve data, you use a client library or console to work with the database. Yay.
And while DynamoDB's NoSQL approach is great for software devs, it can become a bottleneck when data engineers or analysts want to apply it to things like analytics. If you want to explore or model the data beyond key-value lookups or secondary index queries, you'll either need to denormalize the data within DynamoDB or move it to a different data structure entirely.
As an aside, NoSQL databases like DynamoDB can be tricky when non-developers (i.e. data engineers and analysts) want to explore or utilize the data. These roles are typically more comfortable with SQL and are less inclined to want to run queries via a console or client application.
Note: You can query DynamoDB tables with SQL using the right tools.
Cloud vendor lock-in
As far as clouds go, AWS is a good one. It's the most popular cloud in the world, in fact. If you're on AWS and don't intend to leave, then DynamoDB is great.
That said, as with any AWS product, DynamoDB requires you to be on AWS. This means you'll only gain efficiencies when using other tools in the AWS ecosystem.
This isn't necessarily a problem unless you or your company are on GCP or Azure, in which case you won't be able to utilize DynamoDB in a performant or cost-effective way.
DynamoDB Alternatives
So what do you do when DynamoDB isn't the right solution?
For use cases where DynamoDB is well suited, but you can't use it either because you're not on AWS or you have some other constraint, you can use open-source tech like MongoDB or Apache Cassandra. Or if you're on another cloud, you could use something like Firestore/Datastore/BigTable (GCP apparently has 3 NoSQL databases!) or CosmosDB (Azure). These databases function similarly to DynamoDB and will offer many of the same benefits within non-AWS environments.
For use cases where DynamoDB is not well suited, you need to find another technology that better meets the need.
For example, on AWS, you might want to replicate data from DynamoDB to Redshift or Athena for business intelligence or ad hoc analysis use cases.
Real-time analytics with DynamoDB
While DynamoDB is a great real-time transactional database, it will degrade when used for real-time analytics. In these scenarios, you'd want to augment DynamoDB with something like Tinybird, which can be deployed on AWS and is well-suited for handling complex analytical queries at comparable latencies to DynamoDB.
Tinybird offers a native DynamoDB connector that manages backfill and streaming upsert operations from DynamoDB to tables in Tinybird. Tinybird uses DynamoDB Streams to maintain an up-to-date replica of your DynamoDB tables within a highly available columnar database built specifically for real-time, user-facing analytics.
Tinybird uses SQL as its query language, so data engineers and data analysts can build real-time data products with a language they're already familiar with.
And for application developers, Tinybird's single-click API generation and hosting eliminates a lot of the work needed to integrate real-time analytics pipelines into user-facing applications.
For more information about using Tinybird and DynamoDB together for real-time analytics on AWS, check out these resources: