Enriching Kafka streams for real-time queries
If you are using Kafka to capture large quantities of events or transactional data, you are probably also looking for ways to enrich that data in real-time. Here is how to do it with Tinybird.


If you are using Kafka to capture large quantities of events or transactional data, you are probably also looking for ways to enrich that data in real-time.
Let’s say you are pushing e-commerce transactions that look like the following to a Kafka topic:
Suppose you want find out things like:
- what your top selling products are,
- what your total revenue per product category is,
- who your most successful supplier is, or
- where do your customers come from
To get those metrics, you're going to want to enrich that partkey with information about the product, that suppkey with the supplier’s information, and that custkey with relevant information about the Customer.
There are two ways to go about this with Tinybird; for both of them, you are going to need those additional dimensions within the database. So let’s first generate a lot of Customers, Suppliers and Parts and ingest them.
We will use a modified version of the Star Schema Benchmark dbgen tool to generate fake data quickly and in large quantities. Like so:
Now you can just post these CSVs to Tinybird’s Datasources API, and Tinybird will figure out the data types and ingest the data automatically:
Just like that, you have your dimension tables as Data Sources in Tinybird:
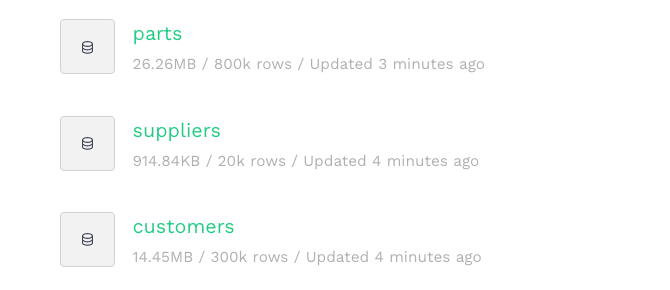
Lastly, we’ll need the actual line orders for every purchase - we will create an empty Data Source in Tinybird to receive the records we'll be ingesting via Kafka.
In order to push line orders to a Kafka Topic, let's use a simple Kafka producer written in Python that will read the individual line orders generated by dbgen. Here is how the producer looks:
The producer receives the file name with the line orders, and it pushes all of them one by one to the Kafka topic (orders).
In the following snippet, you'll see we can create a Python environment and start the producer (assuming you have Kafka and zookeeper running already):
This is now pumping line orders into Kafka, but they aren't yet being consumed. Lets use a consumer (source code) to read those orders in chunks of 20000 and send them to Tinybird, so that they get ingested directly into the lineorders Data Source we created earlier.
When running the consumer, we specify what Kafka topic it needs to read from (again, 'orders') and what Data Source in Tinybird it needs to populate, as well as the API endpoint. Like this:
The consumer starts reading all those Kafka events at a rate of approximately 20K records per second and pushing them in chunks to Tinybird, and it will keep going while there are lineorders to consume. Let’s look at how the data is shaping up via the Tinybird UI:
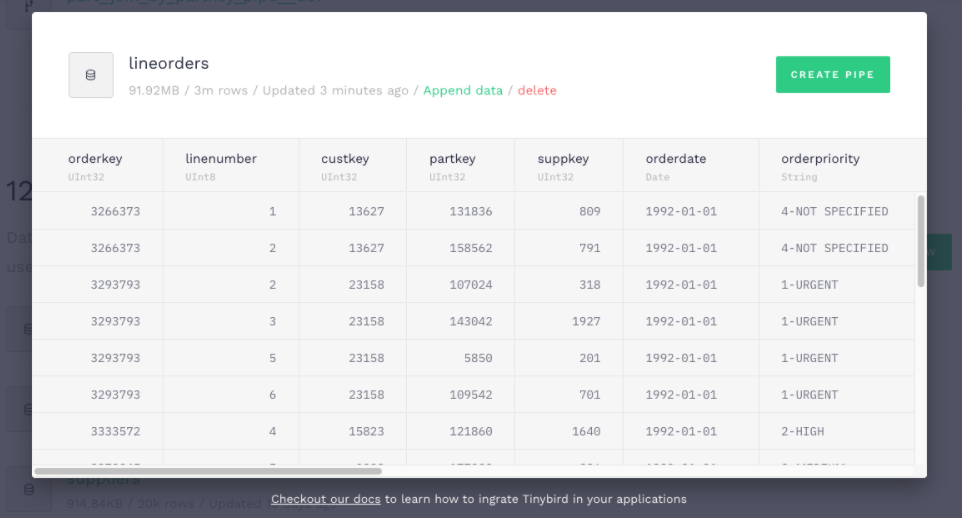
Looking good!
Enriching the classic way
Now that you have the e-commerce transactions (line orders) coming in as well as all the required dimension tables (Customers, Parts and Suppliers), you can start enriching content with regular SQL joins.
Let’s say you want to extract how many parts of each category are sold per year for each country, and limit the results to years 1995 to 1997. You can create a Pipe and write an SQL query like this one:
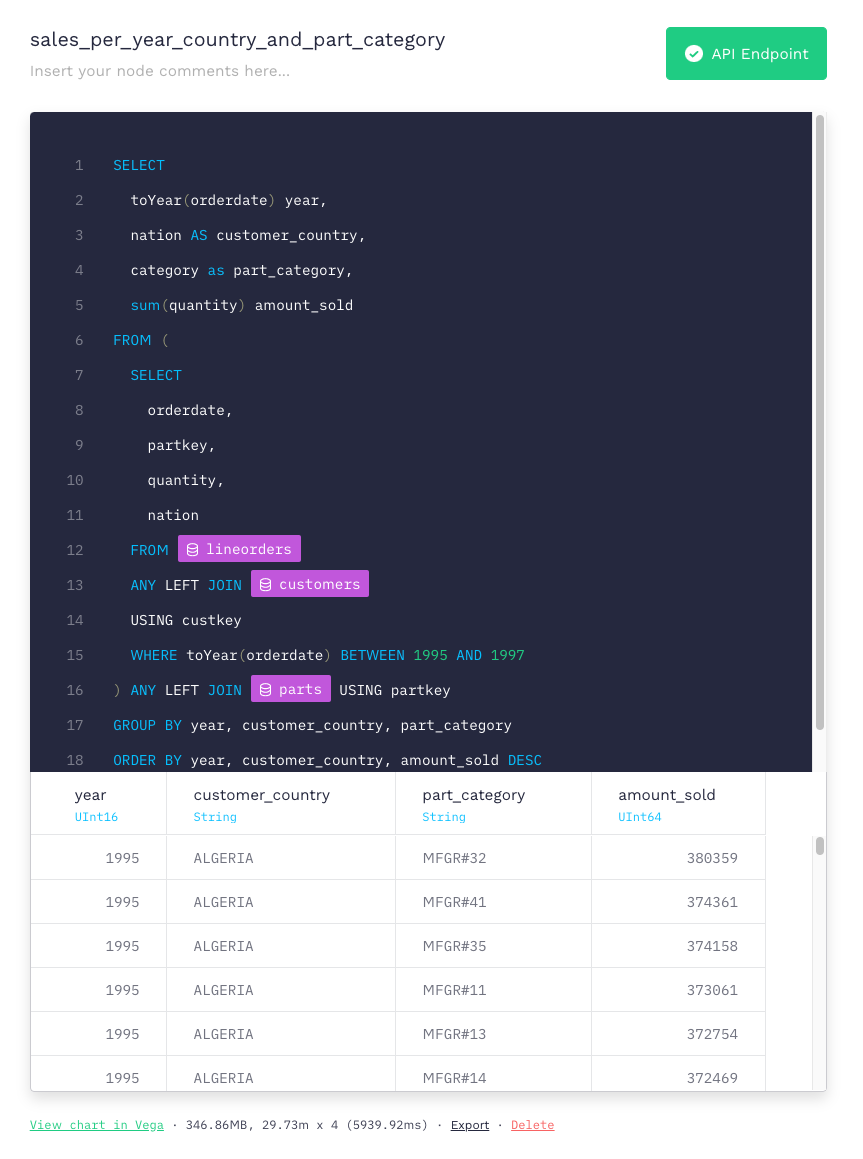
Unoptimized, with over 60M line orders in total, that query can take almost 6 seconds to run; this is fine if you are only performing it every once in a while, but if you want to expose multiple API endpoints and hit them with multiple requests per second from live applications (which is what you always want to do with Tinybird), those seconds will add up. And things would only get slower as data grows.
You could obviously make that faster by parallelizing the query amongst many more CPU cores and make it faster; however, we can also speed it up with a different approach.
Enriching at ingestion time
One of the best things about ClickHouse, the columnar database that powers Tinybird, is that it is extremely efficient at storing repetitive data. That means that, unlike in transactional databases, denormalizing data won’t have a huge impact on the amount of data you have to read when performing queries.
In Tinybird, you can create “Ingestion” Pipes that materialize the result of a query into another Data Source. This helps us enrich data as it comes into Tinybird; rather than performing JOINS every time you query the data, you perform those JOINS at ingestion time and the resulting data is available for you to query in a different datasource.
Here is an example of one of those Ingestion pipes through our UI.
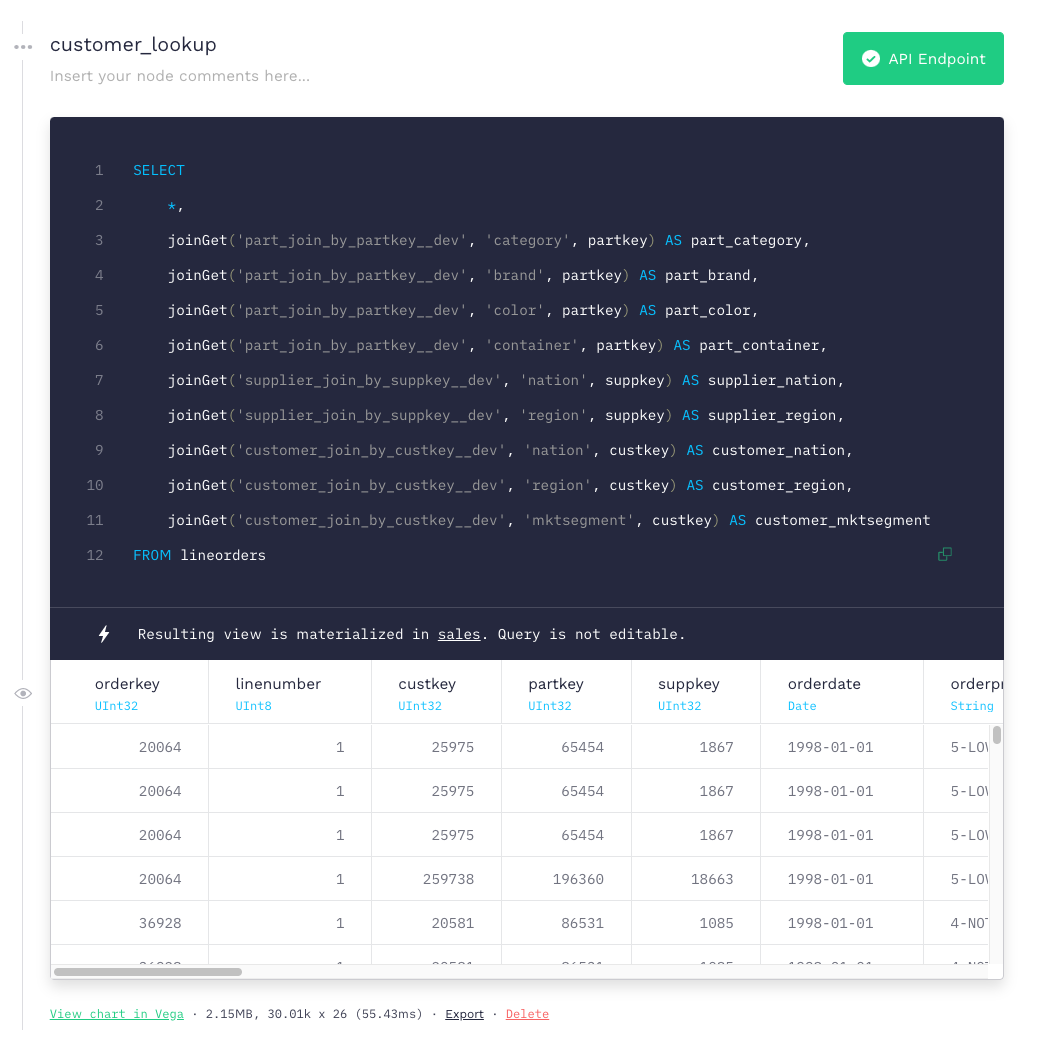
What this Pipe is essentially doing is materializing the result of that query from the lineorders Data Source to the sales Data Source, and it happens every time new data gets ingested.
As you can see, it is adding every column from lineorders plus a number of other columns from the Parts, Category and Supplier dimensions, enabling us to have everything we need for one or more analytics use-cases in a single place.

It uses joinGet, a ClickHouse function that enables you to extract data from a table as if you were extracting it from a dictionary; it is extremely fast and it requires that the tables you extract from to be created with a specific ClickHouse engine: that is why in the query you see those part_join_by_partkey or supplier_join_by_suppkey Data Sources - we create them automatically in these scenarios to enable fast joins at ingestion.
If you build a query to extract the same results as before but directly through the denormalized sales Data Source, it would look like this:
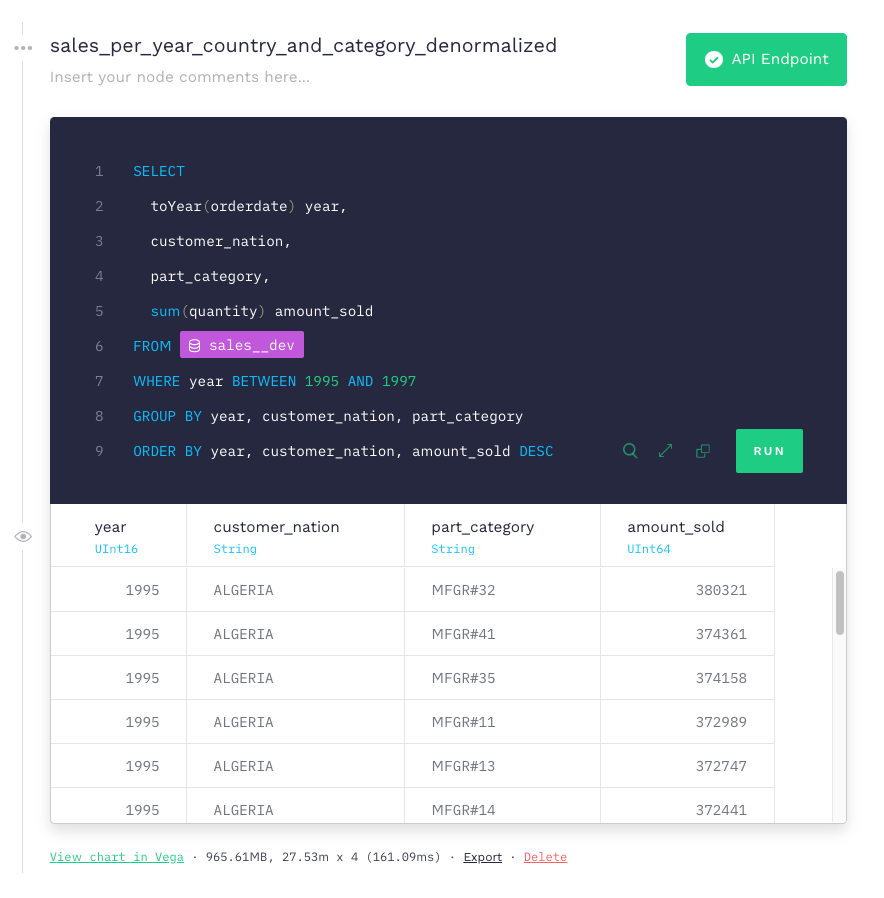
If we hit that endpoint again, we get the same results but now in 161ms (vs almost 6 seconds), which is about 37 times faster.
The beauty of this is that:
- you can enrich data as soon as it hits Tinybird,
- you can do it at a rate of hundreds of thousands of requests per second, whether this data comes through Kafka or any other means,
- every time new data gets ingested, only the new rows need to be materialized,
- while all that data is coming in, you can keep hitting your Tinybird real-time endpoints with abandon and we ensure that results are always up to date, with all the data you require for analysis
Do you use Kafka to capture events? If you'd like to enrich them in real-time, give Tinybird a try. The free Build Plan is more than enough for simple projects, and it has no time limit and no credit card require.
Need an assist? Join our Slack community for questions and support.