How to scale a real-time data platform
Tinybird is an enterprise-grade data platform with large customers processing huge amounts of data. Learn how we scale to support their use cases.


People often ask me how Tinybird will scale to support their use cases. It's a major source of anxiety; a lot of people have had bad experiences with vendors that claimed they could scale, throwing out buzzwords like "serverless" or "elastic" without really understanding the consequences of petabyte data loads and massive real-time architectures.
Tinybird is an enterprise-grade data platform that supports many very large customers processing very large amounts of data. We think about scale every day, every hour, every minute. We know how and when to scale infrastructure for our customers during peaks like Black Friday or when they start to experience steady-state growth.
Scale is always on our minds. So, I thought I'd write about it.
Tinybird gives us everything we need from a real-time data analytics platform: security, scale, performance, stability, reliability, and a raft of integrations.
- Damian Grech, Director of Engineering, Data Platform at FanDuel
This is how Tinybird scales.
First and foremost, our philosophy for scaling is simple: "First, optimization. Then, infrastructure." Hardware is expensive, and logic is "free". So we always look for ways to optimize SQL queries to reduce the amount of resources required to serve their use cases.
But of course, it's more nuanced than that. To understand how Tinybird scales on a case-by-case basis, you must first understand the architecture.
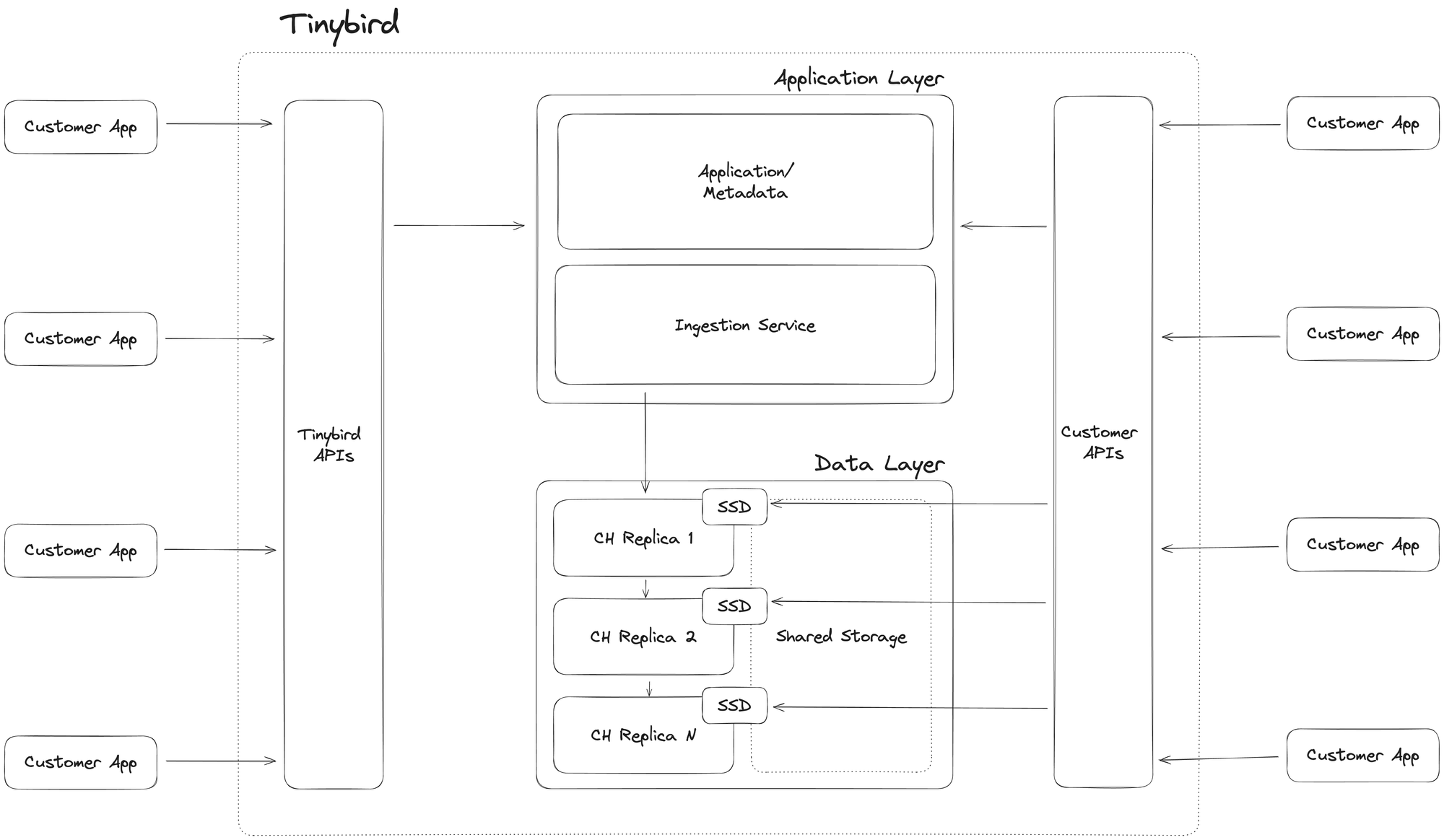
The basic Tinybird architecture
At a high level, Tinybird is a real-time data platform built around a real-time database (ClickHouse). We have several database replicas to manage our customers' loads, and the number of replicas varies based on what we're supporting at any given moment. The database replicas have shared storage, typically on S3 or GCS, and each replica has a fast cache in local SSD disks to speed up critical queries.
In front of the database, we host managed connectors for data ingestion from various streaming (e.g. Kafka, Confluent) and batch (e.g. Snowflake, S3) data sources, and we also manage things like user interactions, version control, query management, etc.
All of these are integral pieces of the platform. We're not just a DBaaS scaling a database cluster for our customers. We're also scaling their streaming data ingestion and the high-concurrency, low-latency APIs they create from their database queries.
What we mean by "scale"
Also, to understand how Tinybird scales, you must understand what "scale" means. What order of magnitude are we talking about?
Here are some real-world examples from some of our customers that help to wrap your mind around our level of scale:
- A top-five global clothing retailer uses Tinybird to build real-time product recommendations on their eCommerce site. On Black Friday in 2023, they ingested 4.3 billion events (7.5TB) of streaming data and supported 9.5k peak API requests per second with these latency metrics:
- p90 - 56 ms
- p99 - 139 ms
- p999 - 247 ms
- p9999 - 679 ms
- Error rate: 0.000002%
- A CDN client ingests into Tinybird all requests made to their system. This amounts to about ~250K events per second on average, with peaks of ~600K events per second.
- Other customers build use cases with streaming data, such as real-time stock management, web analytics, internal analytics, and more. They typically load about 20-30K events per second from Apache Kafka or other streaming sources into Tinybird, with peaks of 300K events per second.
- Some customers ingest more than 1 million events per second.
So, roughly speaking, we're dealing with single customers that can exceed 1M events per second of streaming data ingestion, 10k API requests per second processing several petabytes of data every day, and achieving request latencies below 50 milliseconds for the majority of queries.
This is no small feat.
We had noticed how fast Tinybird could process events, so we decided to go even further and send more events from even more forms to Tinybird. We didn’t even have to warn them. The entire time, P99 latency stayed beneath 100ms.
- Juan Vega, Software Engineer at Typeform
There's no one way to scale
Of course, the scale depends on the use case. Some clients don't have large ingestion loads, but they make a lot of heavy concurrent queries. Some clients don't have big queries, but they need to have heavy loads of streaming data available for query in less than a second. Some customers have both.

In general, here's how we scale to handle certain use cases:
Scaling query concurrency
Customers like FanDuel, Canva, Vercel, and many others build on Tinybird because they can create real-time APIs that serve thousands of concurrent requests in milliseconds. As customers scale their query concurrency, here's what we do to maintain latency below acceptable levels:
- Add more replicas, OR
- Add more CPUs to each replica, OR
- Both
In this case, storage is common and doesn't necessarily need to scale. Adding replicas is straightforward and scales the compute necessary to achieve high concurrency at low latency.
Reducing latency
Our Enterprise customers often have strict latency SLAs that we're contractually obligated to keep. We are bound to maintain percentile response times below certain levels even as streaming ingestion increases or the customer experiences peak concurrency.
Often this looks like scaling individual queries. For critical use cases, we identify queries that can benefit from additional CPU cores, and scale them up.
Of course, depending on the query, the way we scale can change. Sometimes it's as simple as changing a configuration parameter in the endpoint. Other times, we might use all the available replicas to run a single query in parallel.
The goal is always to ensure that all of our customer use cases, from top to bottom, can scale on demand.
Scaling ingestion
Remember, we must be able to simultaneously scale writes and reads, constantly aware of the impacts of ingestion on consumption and vice versa.
When it comes to scaling ingestion, we have a few tricks up our sleeve. Fortunately, we can use all of the replicas as writers if we need to because we use shared storage for the replicas, and any replica can write to it.
That said, we're currently only relying on one writer in production. A lot of the scaling happens even before data hits the database. We have built and are constantly improving the services that handle ingestion, doing the heavy lifting before data touches the database.
Hardware is expensive, logic is free.
From a technical standpoint, we can always assign more CPUs or create more replicas, but scaling hardware is expensive. So, as I mentioned above, before we touch the infrastructure, we look at the software and the logic.
Working in real-time requires a different mindset, especially a different way of thinking about constructing your SQL queries most efficiently. We support our customers by identifying underperforming or resource-hogging queries, and we work alongside them to optimize their queries to read less data.
Materialized Views are a powerful lever here for scaling without hardware. In Tinybird, Materialized Views can pre-calculate aggregates incrementally, as new data is ingested. They have the power to reduce query scan sizes by several orders of magnitude, so we use them often as optimization techniques for scaling concurrency and latency without adding hardware.
This is the magic of Materialized Views in Tinybird.
— Tinybird (@tinybirdco) June 8, 2022
Before MV:
- 3k requests/day
- 45 GB avg scan size
- 2.0s avg latency
After MV:
- 3k requests/day (Δ0%)
- 2.5 GB avg scan size (Δ-99.99%)
- 30ms avg latency (Δ-98.5%)
Speed and savings, my friends. Speed aaaand savings. pic.twitter.com/yRWO9R4PPr
Beyond that, we help our customers follow best practices for writing SQL in real-time data pipelines so that they scan less data.
Some more reading about how we scale
We've written some great blog posts about scale in various aspects of our platform. I've consolidated them below for further reading in case you're interested:
- The Hard Parts of Building Massive Data Systems with High Concurrency addresses eight problems with trying to scale high-concurrency systems and how we think about them at TInybird.
- Adding JOIN support for parallel replicas on ClickHouse talks through some of our contributions to the open source ClickHouse project to be able to better support running complex queries in parallel across multiple replicas.
- Resolving a year-long ClickHouse lock contention explains our process for investigating and resolving very fine-tuned performance issues in our underlying database.
- How we processed 12 trillion rows during Black Friday talks about our approach to scale in the early days. We've changed some of our technical approaches to scale since then, but the article helps explain how we've been thinking about scale since the beginning.
- Using Bloom filter indexes for real-time text search in ClickHouse digs into some of the logical approaches to optimizing queries on the database. In this case, we helped a customer optimize full-text search queries using more efficient indexes.