Instrument your LLM calls to analyze AI costs and usage
If you're building AI features, make sure to instrument your LLM calls so you can analyze costs, usage, and adoption. Here are a few examples in Python and TypeScript.



Over the last few years, we've gradually introduced new AI features into Tinybird. Many were small and simple quality of life improvements, such as auto-fix errors, auto-complete code, or auto-generate schemas.
With our latest product release, however, we made a big step forward in our journey to build an AI-native product. We introduced features that shift a lot of work to LLMs, such as creating a full Tinybird data project, writing test suites, generating mock data, or iterating APIs and schemas based on user prompts.
When you're building with Tinybird, you're building with AI:
tb create --prompt: Generate or update resources, even one-shot full data projectstb mock <datasource> --prompt: Create fixture data for a given data source schematb test create <pipe> --prompt: Cover your APIs with tests given endpoint responses
How do we implement AI features?
In The Year of AI Agents™️, we have kept our implementation of these features pretty basic: just an LLM, system prompts, and function calls, with simple loops to auto-fix issues or hallucinations.
We have two backends, one in Python and one in TypeScript.
The Python backend implements all our public APIs, such as the Events, Pipes, and Tokens APIs; these APIs serve all the features to build data projects and provide access to users and metadata databases.
The TypeScript backend is responsible for the frontend API routes and features.
The Python backend implements some of the more complex AI features, such as creating a full Tinybird project from a prompt, using AI to write tests, generating mock data, or iterating existing projects.
The TypeScript backend includes simpler features that improve UX in the web app, such as auto-fix features, SQL auto-suggestions, and more.
We use Vertex AI to simplify our implementation, to test different LLM providers and models, and to compare metrics such as cost, latency, errors, time to first token, etc, across models.
We use libraries to simplify our LLM implementations for both Python (LiteLLM) and TypeScript (Vercel AI SDK).
Finally, we use Tinybird to instrument our AI features and analyze LLM usage.
Why instrument LLM calls?
When we add a new feature to Tinybird, we instrument it for all the typical reasons: error and performance monitoring, product analytics, observability, etc.
Beyond that, AI features have specific requirements and metrics that traditional instrumentation doesn't cover. We're still in a moment of discovery and experimentation as we transition into the era of AI natives, so instrumentation is important for learning how to best use LLMs in our applications.
Real-time LLM cost calculations
LLM models can get expensive quickly. By instrumenting our AI apps, we can monitor costs and answer these questions:
- Are certain features or users consuming tokens disproportionately?
- Which models give you the best bang for your buck?
- Are there redundant or inefficient prompts that could be optimized?
LLM performance metrics for production
Measuring performance for LLMs differs from traditional application monitoring, with a new set of metrics:
- Time to first token (TTFT): How quickly does our application start generating a response?
- Model latency: Are certain providers or models consistently slower?
- Error rates: Which prompts or user inputs lead to failed completions?
- Temperature performance: How does adjusting the "randomness" parameter affect response quality?
Cross-model performance metrics
The AI provider landscape is constantly shifting. By centralizing our instrumentation and analysis, we gain the flexibility to:
- Compare performance across multiple providers (OpenAI, Anthropic, Cohere, etc.)
- A/B test different models on the same prompts
- Migrate between providers without losing historical performance data
Detect Issues in AI outputs
Once you've instrumented your pipeline, finding issues with your AI gets much easier:
- Semantic issues, like agents forgetting critical information or misunderstanding user intent
- Objective signals from users, like thumbs up, thumbs down, and regenerations
The best teams are looking at these issues, sending alerts to slack, finding the patterns in them, and creating datasets for evals, fine-tuning, etc. This is one area where an advanced monitoring platform like Dawn comes in handy.
Tracking AI feature adoption
Just like traditional features, instrumentation helps with understanding user engagement patterns:
- Which AI features do people use most?
- Are there user segments that rely more heavily on certain AI capabilities?
This helps us choose the right LLM for our different use cases by keeping all metrics centralized, giving us the ability to measure and adjust as the AI ecosystem evolves.
How to instrument LLM usage in Python with LiteLLM
We use LiteLLM, a lightweight Python library, to interface with the LLMs via our Python backend. LiteLLM allows us to use any LLM with a simple and easy-to-use API.
We use a handler that hooks into LiteLLM callbacks to send events to the Tinybird Events API. You can see the implementation here.
Then you do your usual LLM calls, enriching with your custom metadata.
How to instrument LLM usage in TypeScript with AI SDK
We use the Vercel AI SDK, a popular choice for many TypeScript developers, to call the LLM from our TypeScript backend.
To instrument our calls, we use a common pattern of wrapping the underlying LLM provider API in a custom function that enriches the LLM call with our custom metadata.
Then we use the wrapped model in the Vercel AI SDK.
You can see the implementation of the wrapModelWithTinybird function here.
What LLM data do we track?
We send LLM events from our backends to the Events API, which supports up to 1k RPS by default, so scale isn't a concern.
A Tinybird data source called llm_events captures these dimensions and metrics:
- Model, provider, and API key information
- Timing data: start time, end time, duration, time to first token
- Token usage: prompt tokens, completion tokens, total tokens
- Cost per request
- Success/failure status and associated error information
- Custom metadata: project, environment, organization, user ID
- And the full prompt and completion messages, that can be used to calculate embeddings and more
The schema for llm_events looks like this:
We instrument the LLM calls with custom metadata (project, environment, organization, user_id) saved in the proxy_metadata column. This information is used to join LLM calls with other product events, like API calls, errors, billing, etc. We could also use it for user-facing analytics.
Once we had instrumented our LLM calls, we built a web app to track in real time the key metrics we care about. This tool is currently only used internally by Tinybird's product and AI engineers, but it’s designed to support multitenancy and can be easily adapted to build user-facing LLM usage and analytics dashboards.
You can see a demo of the app here (with mock data). We're still fine-tuning, but we plan to release it next week as an open source template so you can use it and adapt it to your needs.
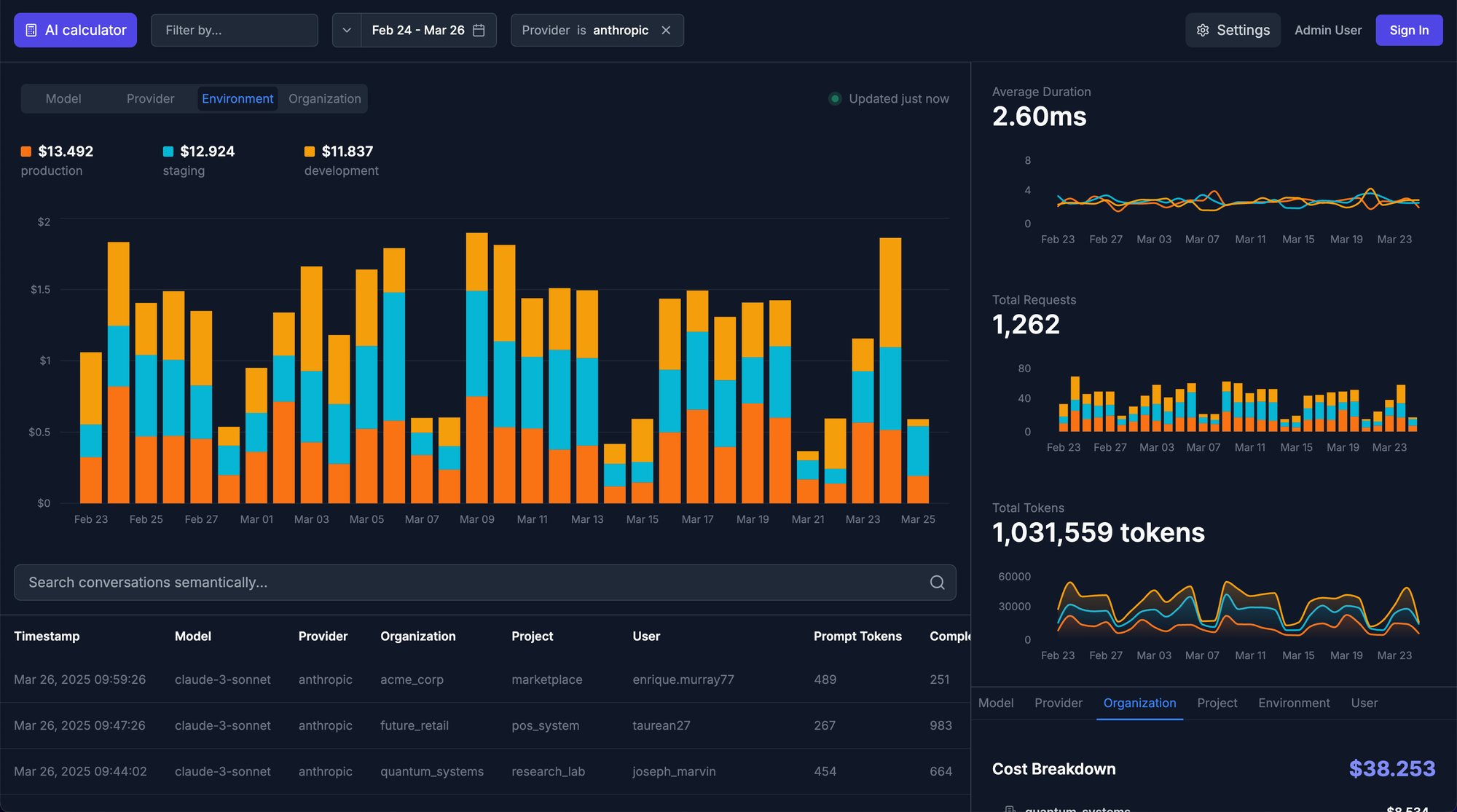
You can see how we extract the metrics to calculate LLM costs in the project repo.
Start instrumenting your AI application
Instrumenting your AI application isn't complicated, but it has a few different requirements compared to traditional product instrumentation. Start by identifying the key metrics you want to track, set up a basic event logging system, and gradually refine your approach as you gather more data. You can vibe code a web app to visualize the metrics, or wait until we share our template next week ;).
The AI landscape is constantly changing. Build a solid foundation for AI instrumentation now, and you'll be well-positioned to optimize costs, improve performance, and make data-driven decisions about your AI strategy as your application scales.
Here are some resources to help you instrument your AI applications in the same ways we do at Tinybird: