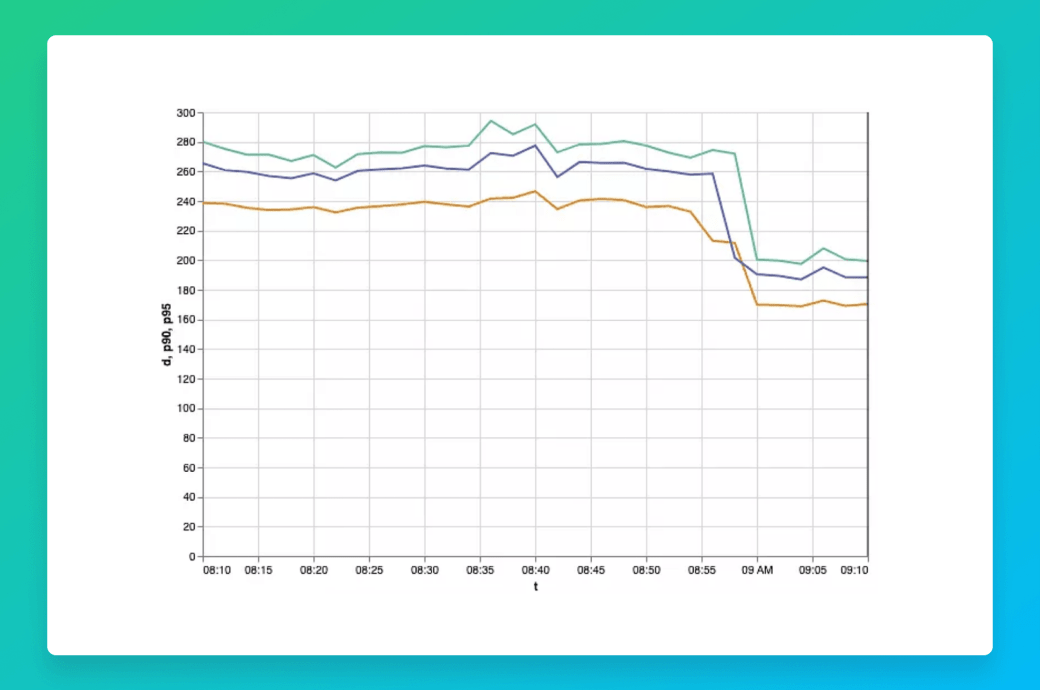
The Data Base Designing a faster data model to personalize browsing in real time Optimizing API endpoint performance for browsing personalisation.
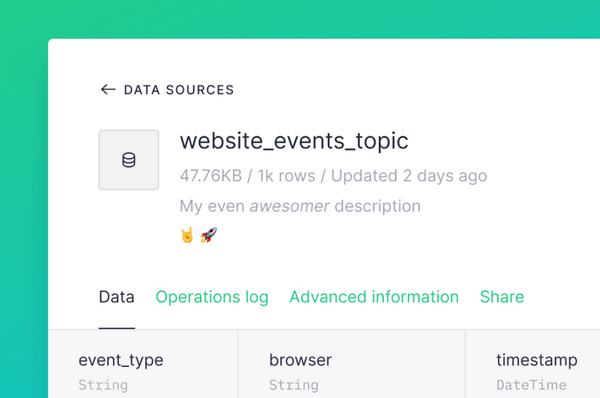
Product updates Changelog #20: Data Source descriptions and beta testing of Parquet ingestion Document your Data Sources by adding descriptions just like you do for pipes and nodes
Tinybird news The realtime data stack. What’s next for Tinybird. Sign up and start turning data into realtime insights, actions and business value.
Tinybird news Tinybird is out of beta and open to everyone Sign up and start turning data into realtime insights, actions and business value.
Tinybird news Welcoming new senior leaders to Tinybird Tinybird announces four new senior leaders to help deliver even more value to customers at a key stage of growth.
I Built This! Visualizing your Twitter timeline sentiment with Tinybird What if you could measure happiness and sadness, the peaks and troughs, just by analyzing the sentiment of your Twitter timeline?
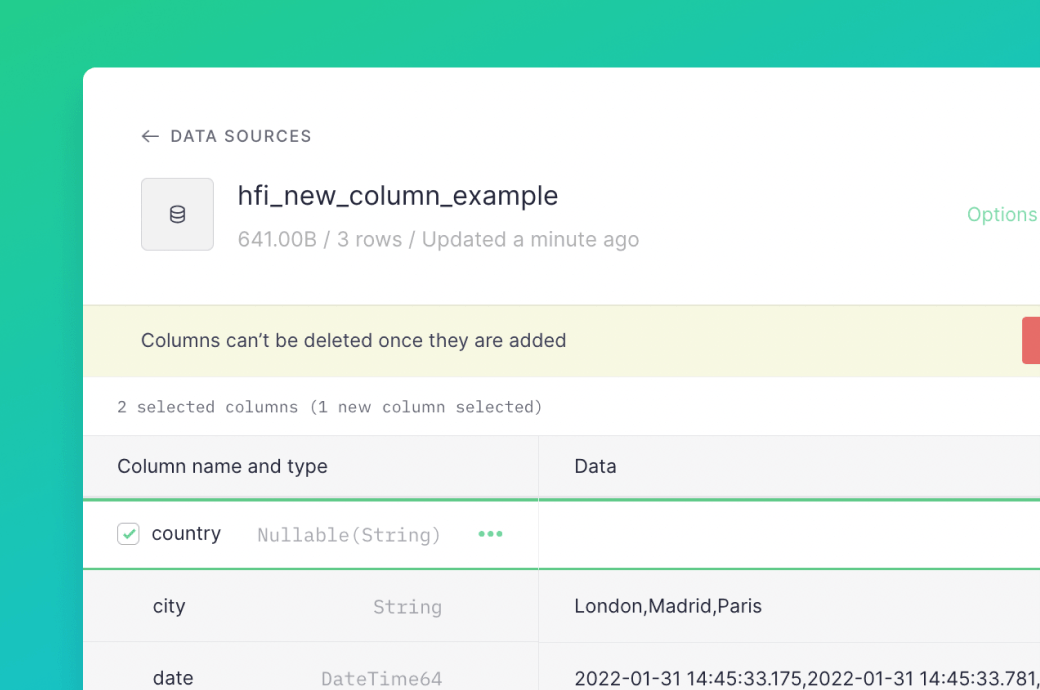
Product updates Changelog #19: Adding new columns in high-frequency ingestion and more New columns in high-frequency ingestion, passing parameters between pipes and design improvements
Product updates Tiny Updates: Drag and Drop to Rearrange Nodes in a Pipe New feature: dragging and dropping to rearrange the nodes in a Pipe.
Product updates Changelog #18: High-frequency ingestion, handling NDJSON files and more product enhancements High-frequency ingestion, handling NDJSON files, cascading partial replaces and more product enhancements
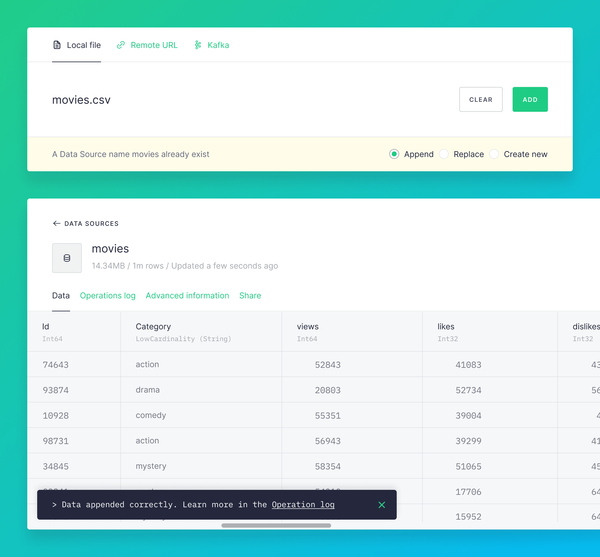
Product updates Add data from CSVs with different column orders Add data to a Data Source from a CSV, even if the columns are in a different order to the one used when the Data Source was created.
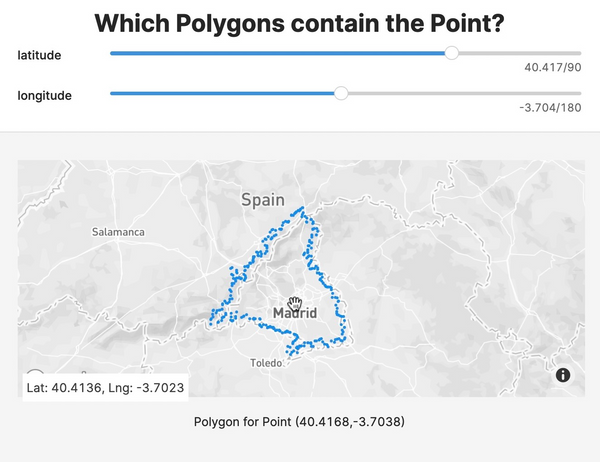
The Data Base Spatial Indexing aids Finding which Polygons contain a Point Speed up your queries by using a spatial index to select fewer polygons before testing if a point is inside a polygon.
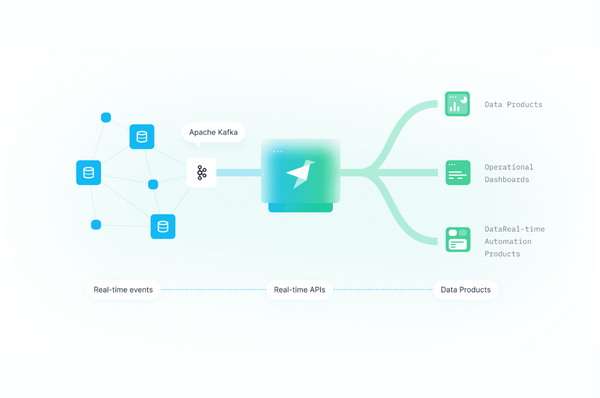
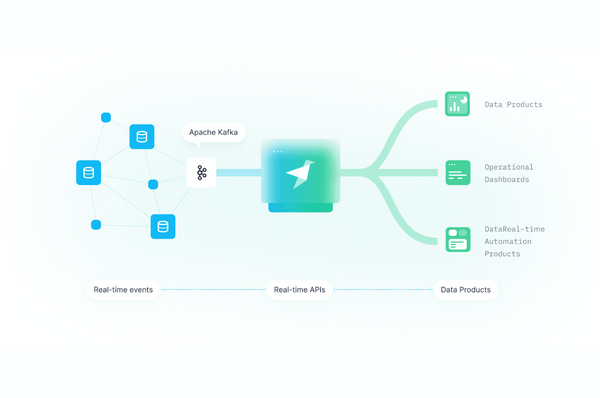
I Built This! From Kafka streams to data products Productize data ingested via Kafka using API endpoints with Tinybird
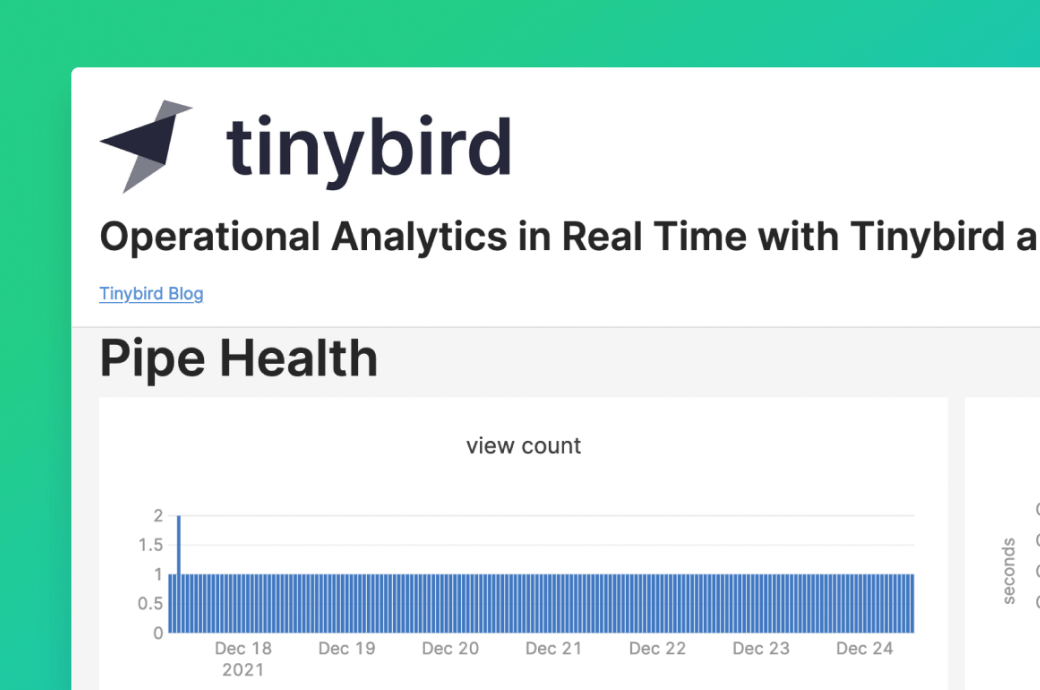
I Built This! Operational Analytics in Real Time with Tinybird and Retool Three steps to create a Retool app or dashboard in minutes to display your operational analytics in real time.
Scalable Analytics Architecture The era of JSON data analytics JSON is the de facto standard for data communication in the web and that's why we are supporting it natively: from a Kafka stream or from local or remote NDJSON files (and very soon in other flavours)
Engineering Excellence Splitting CSV files at 3GB/s Splitting CSV files is a must when dealing with large, potentially larger than RAM, files. But how fast can it be?
Product updates Changelog #17: Guided tour, Kafka ingestion improvements and more Lots has been happening at Tinybird. The team is growing fast and everybody is working to improve the developer experience. Here are some recent features and updates that you may have missed.
Engineering Excellence Performance and Kafka compression The **unmodified** support message we sent to one of our clients outlining potential performance gains through Kafka compression
I Built This! SQL and Python: alerts from predictions Combine Tinybird with pre-coded models to make predictions, compare data in real time to the predictions and alert.
The Data Base ClickHouse Tips #12: Apply Functions to Columns with a Single Call Clickhouse 21 allows some fancy operations packed into multiple columns with SELECT modifiers.
The Data Base ClickHouse tips #11: Best way to get query types A fast and simple solution to know the types returned by a query
Product updates New feature: sharing Data Sources across workspaces From now on, Data Sources can be shared in a read-only way across multiple workspaces. Maintaining only one ingestion process, data can be made available for...
Product updates Changelog #16: Improved Workspace selector, better autocomplete and more Now you can see how many Workspaces you own, the autocomplete is smarter, the CLI and the Kafka connector are better than ever and more.
The Data Base ClickHouse tips #10: Null behavior with LowCardinality columns Does it work? What's actually inserted?
The Data Base Experimental ClickHouse: Projections ClickHouse tags a major release around once a month, which is an order of magnitude more often than similar projects, and it does it while maintaining speed and stability.