Transforming real-time applications with Tinybird and Google BigQuery
Today, Tinybird is excited to announce the launch of our new Google BigQuery Connector, offering Google BigQuery users an easy and reliable method to bring their data to Tinybird where they can query and shape it using SQL and publish it as low-latency APIs to be consumed by their applications.


The goal of every developer is to build applications that feel like they are acting on the freshest possible data. This is a particularly difficult problem for developers working with data warehouses. Most data warehouses are optimized for analytical processing (OLAP), effectively running a low number of sophisticated queries on a giant pile of data. In contrast, transactional processing (OLTP) databases are optimized for a large number of less sophisticated queries (generally over less data).
This results in most data queries from OLAP databases being queried in batches and returned less frequently. For example, we’re all familiar with the “daily metrics report” that enables executives to scan information and make decisions. However, in modern business, decisions can’t be made on data processed, say, overnight. You need to make decisions in real time based on real-time information.
Tinybird runs on Google Cloud and was built to enable the real-time processing of massive quantities of analytical data and making that data available in a developer-friendly way. Developers can ingest data from several different sources, query and shape the data using SQL (a language every developer already knows), and publish the results of those queries as high-concurrency, low-latency APIs, which can be consumed within custom applications and products.
Tinybird makes analytical databases great for developers.
For developers accustomed to building fast applications using accurate up-to-the-second data, going “back” to using data warehouses is a non-starter. Likewise, developers accustomed to building applications on traditional data warehouses can dream up thousands of new scenarios for applications if only they could achieve high concurrency and low latency for each of their queries.
Enter Google BigQuery.
BigQuery is a fully managed, completely serverless, and cost-effective enterprise data warehouse that helps users manage and analyze their data with built-in features like machine learning, geospatial analysis, and business intelligence. As far as data warehouses are concerned, BigQuery is among the best. It’s fast, it’s dependable, it’s easy to use, and it scales with your data.
Today, Tinybird is excited to launch the Tinybird BigQuery Connector, which enables our users to sync their existing BigQuery tables and views to Tinybird, where they can be subsequently shaped and transformed using SQL, and published as APIs to be integrated with custom applications.
This equips Tinybird users with new tools that are purpose-built for developing high-quality applications on top of Tinybird’s analytical databases and will deliver end-users with a high-quality experience that is powered through the low-latency connection between BigQuery and Tinybird.
We’re also excited to announce that we are part of the Google Cloud Partner Advantage Program and available on Google Cloud Marketplace (organizations that use Google Cloud Marketplace can start using Tinybird immediately.)
Today we announce the Tinybird BigQuery Connector, which makes it easy for developers to build low-latency, high-concurrency APIs using data in BigQuery.
The BigQuery Connector is designed to be easy to use, meaning the whole process to sync a BigQuery table to Tinybird takes only a couple minutes. It’s also a fully managed, serverless connector. It doesn’t require the user to set up any infrastructure, and it provides observability, monitoring, and metrics out of the box.
It is also particularly useful for dimensional data since this information is typically never going to be stored in Tinybird as the primary store, but it’s still useful for enriching your events data and building applications with Tinybird. This connector allows you to replicate that data easily and regularly to Tinybird for real-time application use cases.
Already several Tinybird customers are using the beta version of the BigQuery connector, with over 20,000 sync jobs across dozens of tables in BigQuery.
“We love Tinybird, and this is exactly the connector we were looking for. I was able to bring our BigQuery tables to Tinybird with two clicks. It’s so easy to use, I was able to do get it all set up in seconds, by myself, with no additional engineering intervention required."
- Jordi Llópez Martí, Product Manager at Mercadona
The BigQuery Connector is also the first integration to take advantage of Tinybird’s Connector Development Kit (CDK). With the CDK, Tinybird can quickly deliver new Connectors for other leading data products and empower developers to build their own custom Connectors. More information on the CDK will be available soon.
Read on for more about how we built the Tinybird BigQuery Connector and what it’s like to use it.
Once you’re done, you can check out our product documentation to learn about all the details of the BigQuery Connector. If you’re not yet a Tinybird customer, you can sign up for free (no credit card required) and get started today. Also, feel free to join the Tinybird Community on Slack and ask us any questions or request any additional features.
What’s the big deal about BigQuery?
Google BigQuery is a cloud data warehouse service designed and intended to execute long-running, complex queries. While you can dependably get query results in a few seconds for large amounts of data, all queries are managed by something similar to a job pool, meaning there's an overhead (that makes total sense) when you run a query, even a simple one like select 1. That's why some users face hurdles when building real-time data visualizations and interactive applications that need both high concurrency (hundreds of queries per second) and low latency (under 1 second query times).
Like Tinybird, BigQuery offers a serverless architecture, so developers don’t have to worry about infrastructure or scale. One of the reasons it can run queries over large amounts of data at consistent speeds is that it decouples storage and compute such that it can scale on demand. This offers tremendous flexibility as compute resources can be increased on demand and queries can be parallelized.
BigQuery is amazing for business intelligence, but it was not designed for both millisecond latency and high concurrency.
While this is amazing for use cases like business intelligence (BI), data science, and others where a few seconds is more than enough, BigQuery is not designed for millisecond latency and high-concurrency, which is how you can scale user-facing, high-performance applications at a reasonable price.
How we built the BigQuery Connector
Our main goal when building these Connectors is to provide our users with a new, fast, and reliable way to bring their data over to Tinybird. That's why designing a fully managed experience is key.
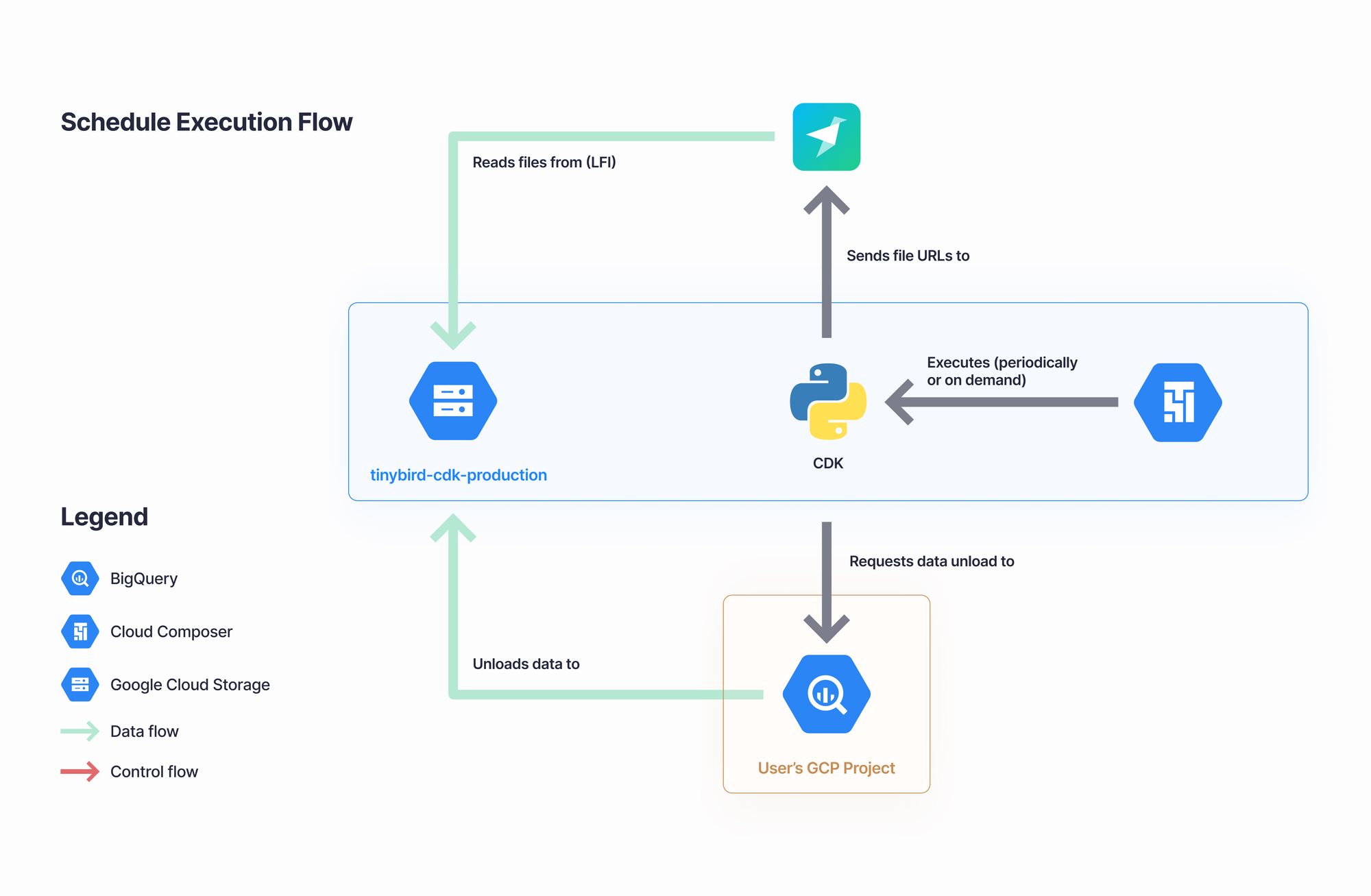
The BigQuery Connector follows a batch-based approach bringing the latest delta with regards to the data stored in Tinybird. This means a background job will run for every sync.
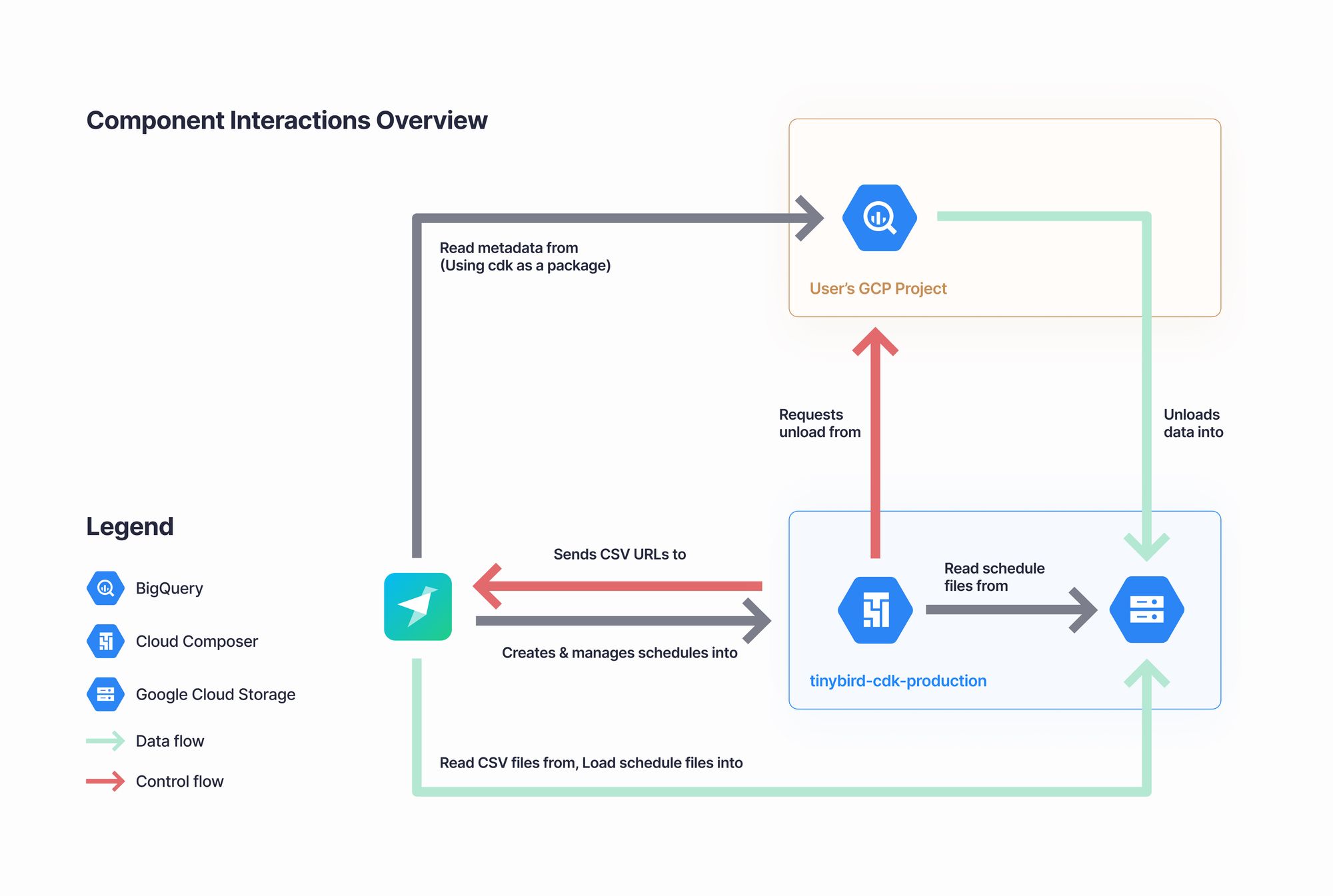
We allow our users to select a BigQuery table or view, choose how often they want to sync their data source, and that's all. This background job is automatically created for the user and scheduled in Google Cloud Composer.
The job definition file (following Airflow's DAG specification) includes the BigQuery resource reference, Cron expression, the generated extract query, and a Tinybird token as a secret. Google Cloud Composer handles the job execution for us, and Tinybird can interact with it using the standard Aiflow API, for example, triggering a manual sync.
Setting up the BigQuery Connector
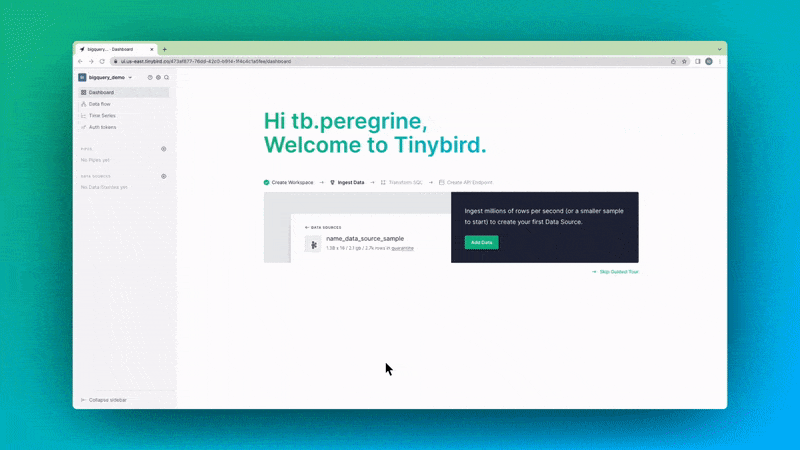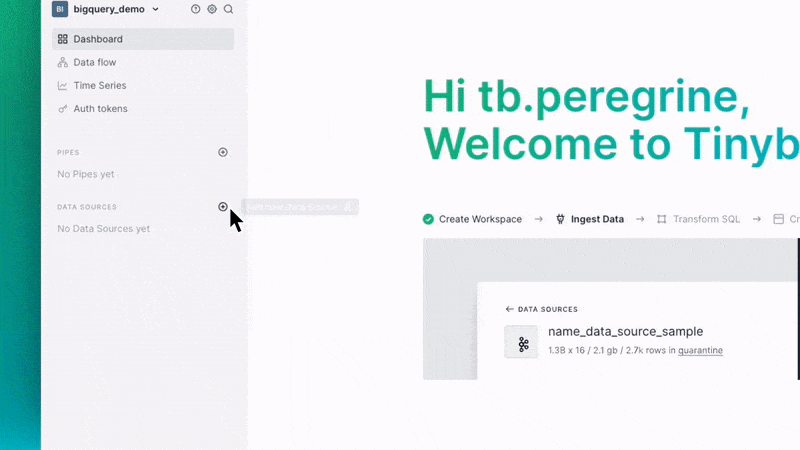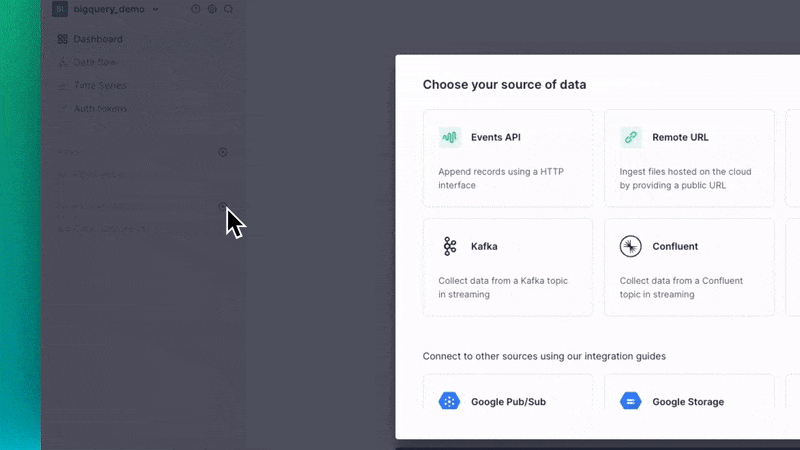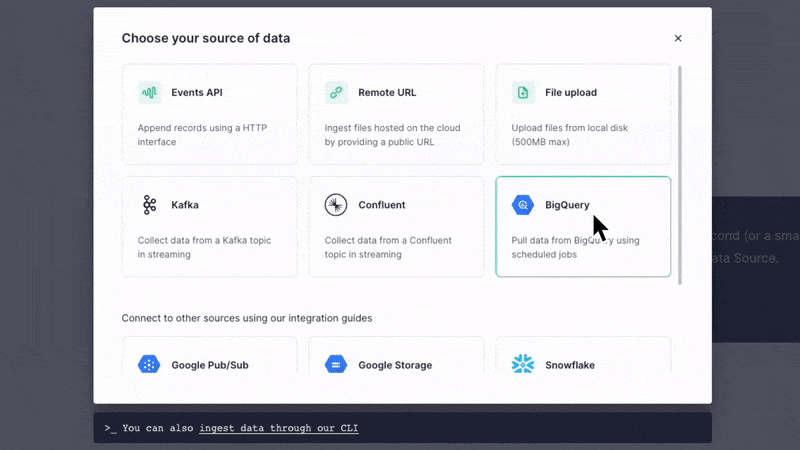
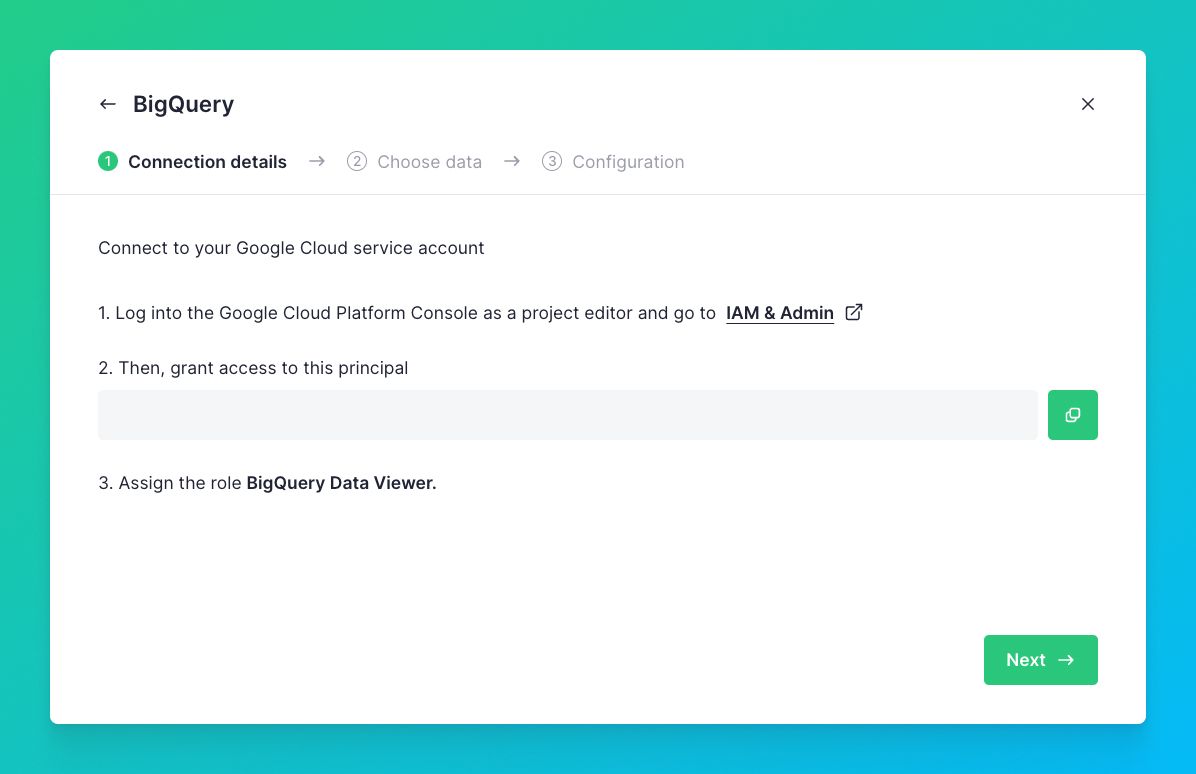
You can set up the BigQuery Connector within the Tinybird user interface. Add a new Data Source as you normally would, and then select the BigQuery option in the resulting dialog box.
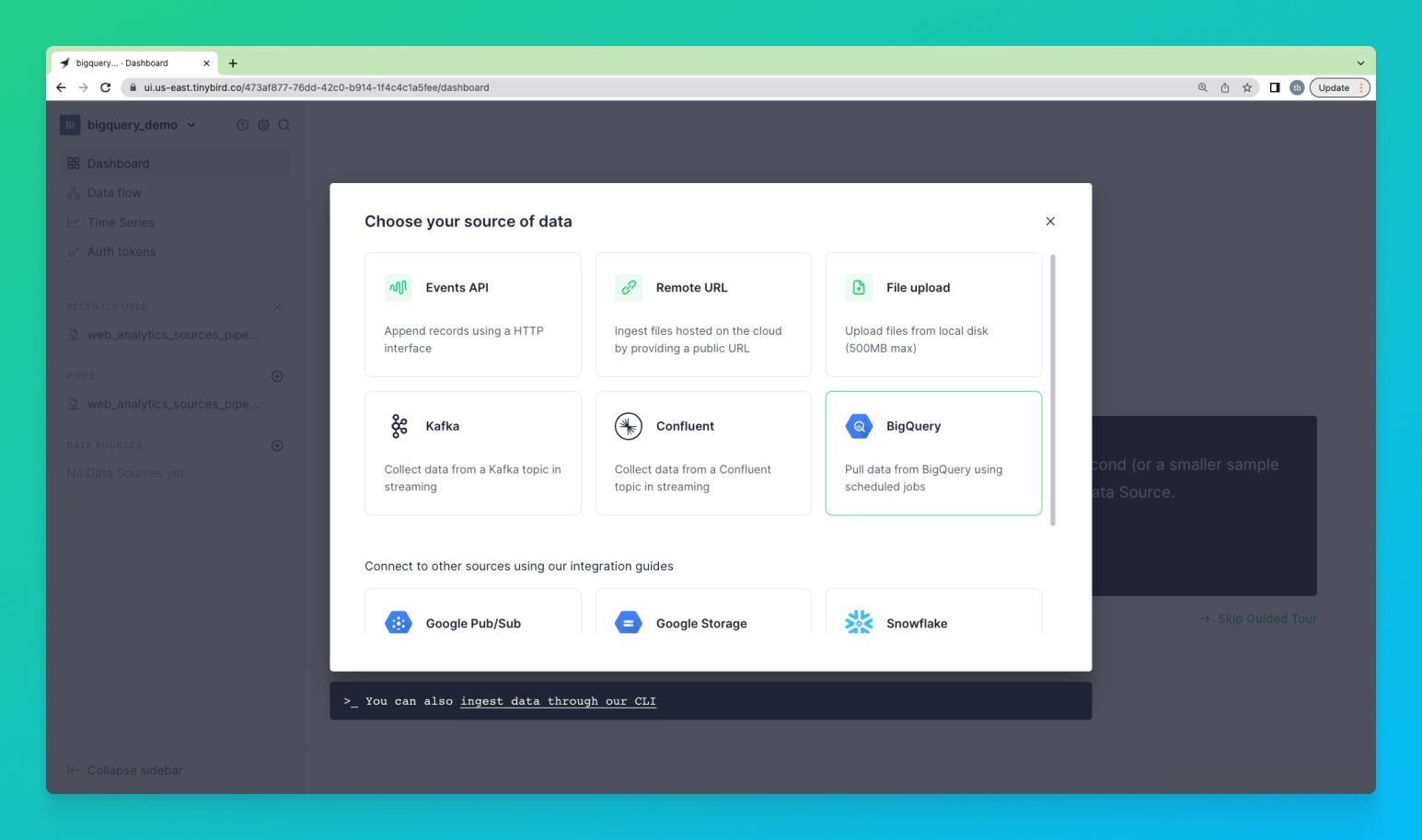
The Tinybird user interface will guide you through setting permissions, selecting which BigQuery tables to sync, and setting the schedule.
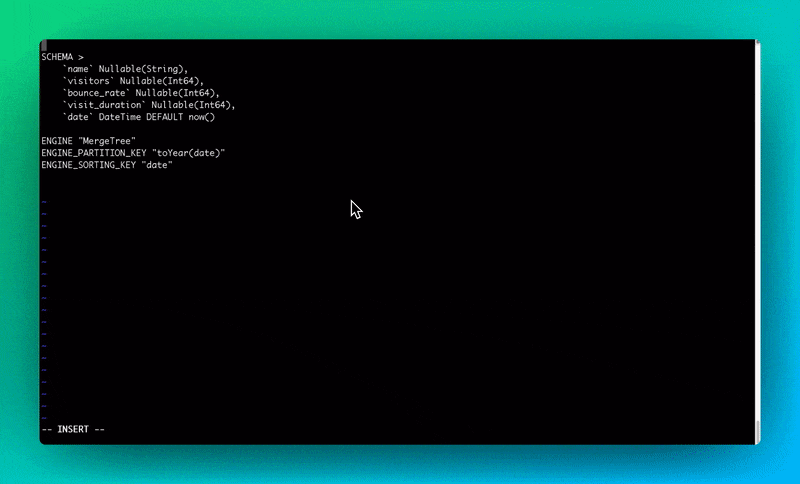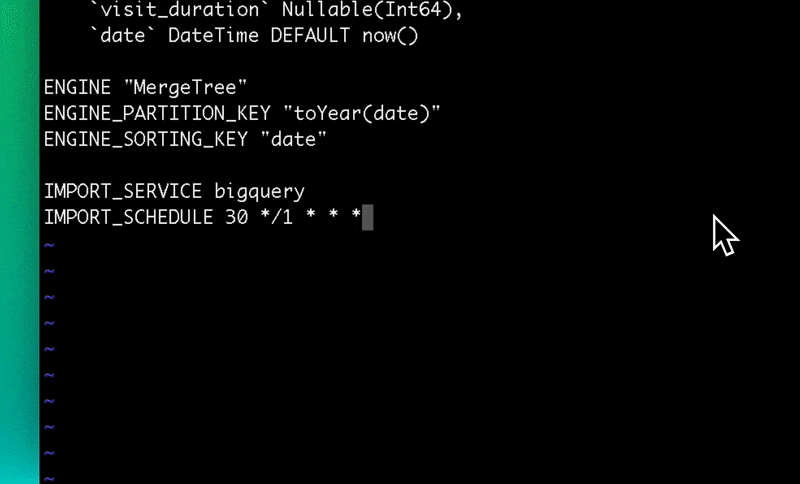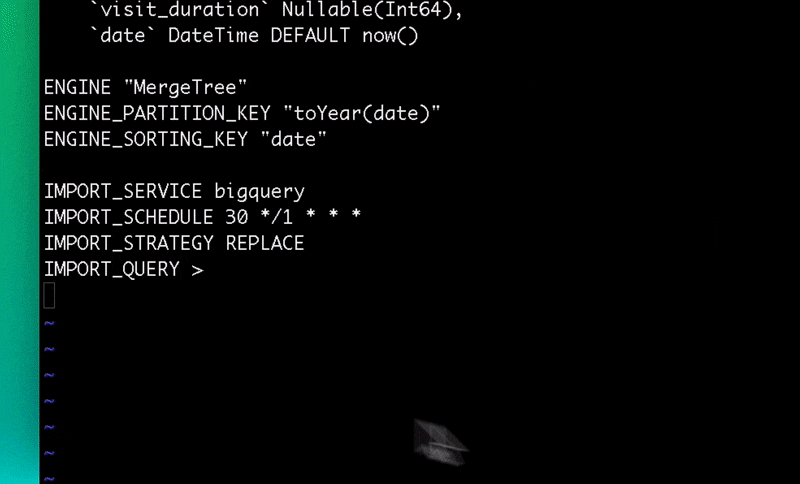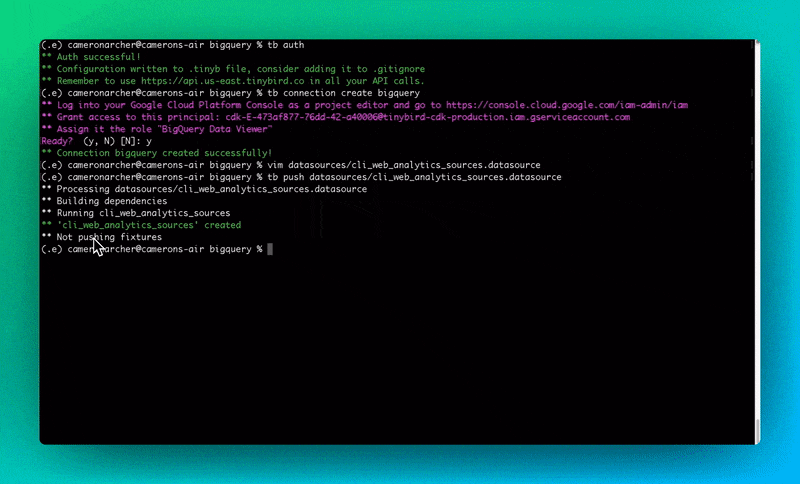
The same steps can be accomplished using the Tinybird command-line interface. This is helpful whether you’re a keyboard warrior or simply want to automate options using scripts.
Maintaining the BigQuery Connector
Being able to tell if your data is correctly in sync is critical. That's why we've built this Connector with top-tier observability in mind.
For a start, you can find a pulse chart under the Data Source details, displaying the last 50 executions and their status. Based on the last execution result, we can determine the Data Source sync status since operations are idempotent.

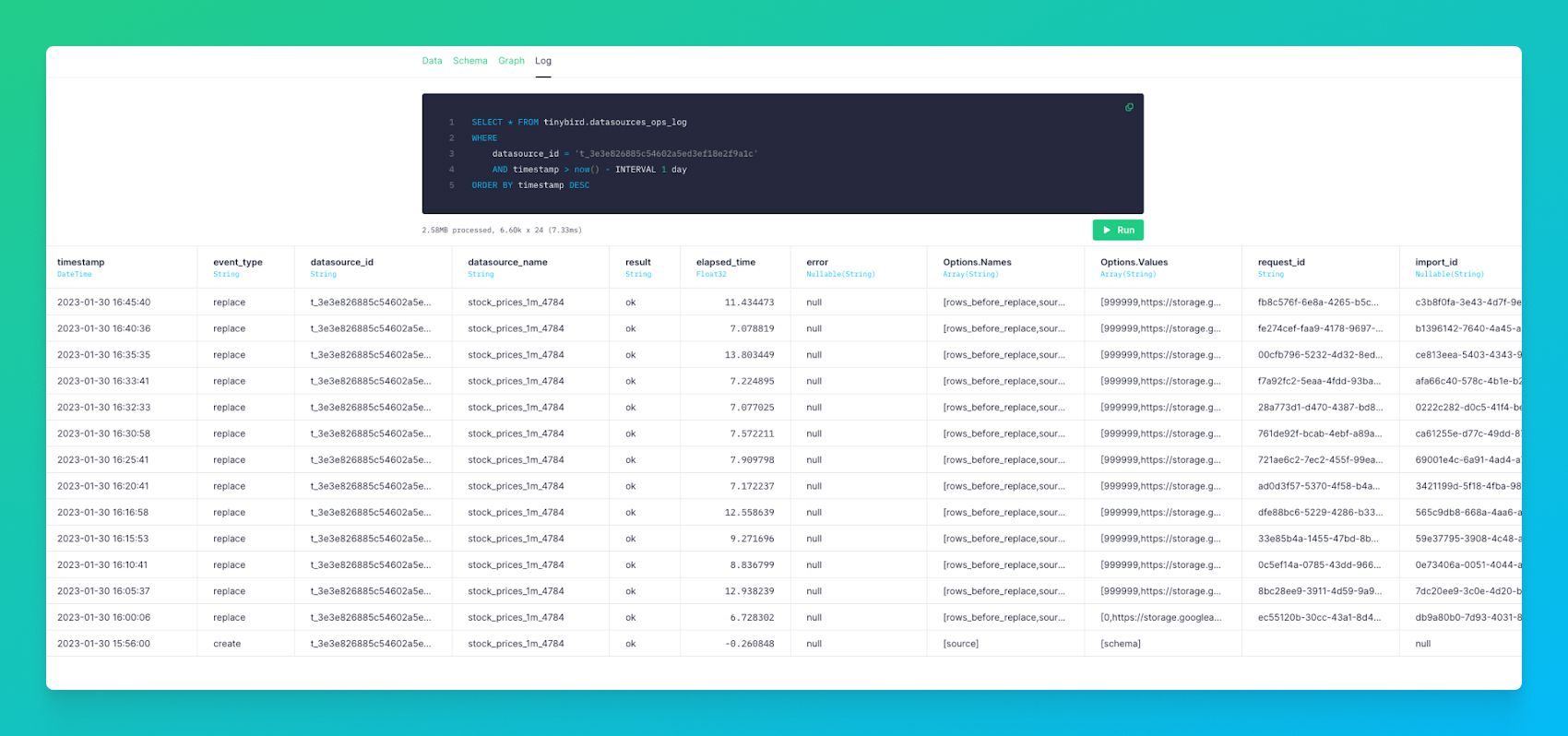
You can also check the Logs in detail, as per usual:
Securing your connection to Google BigQuery
We take security very seriously, and that's why it's a core part of the Connector design. A new Google Cloud service account is created at the Workspace level, and it's never shared with other application components. You just need to grant access to the generated Google Cloud service account specially created for your Workspace, following the instructions.
Get started today
Still want to learn more? Check out the BigQuery Connector docs, or watch the Screencast:
If you’re not yet a Tinybird customer, you can sign up for free (no credit card required) and get started today. The Tinybird Build plan is free forever, with no time limit, but if you need a little more, use the code TINY_LAUNCH_WEEK for $300 off a Pro subscription.
Also, feel free to join the Tinybird Community on Slack and ask us any questions or request any additional features.
And, if you’re keen to learn more about the BigQuery Connector, join our Live Coding Stream on March 8th. Sign up to be notified when the Live Coding Stream starts.