Real-Time Data Ingestion: The Foundation for Real-time Analytics
Real-time data ingestion is Step 1 for building real-time data pipelines. Read this guide to master real-time data ingestion and its underlying architecture.


Real-time data is addicting. Once you start building real-time data pipelines that power revenue-generating use cases, you’ll never go back.
But working with real-time data is a multi-step undertaking. You must capture the data, store it, process it, and expose it - all within milliseconds. In this blog post, we’ll dig into Step 1, the foundation of any real-time streaming data architecture: Real-time data ingestion.
You’ll learn the definition of real-time data ingestion, why it matters, and the use cases it can make possible. Plus, you’ll receive guidance on how to build systems that can support real-time data ingestion.
What is Real-Time Data Ingestion?
Real-time data ingestion is defined as the process of capturing data is soon as it is generated and making it available for use by downstream consumers and use cases. It's the first step in the multi-step process of building event-driven architectures to power real-time analytics.
What is the main objective of real-time data ingestion?
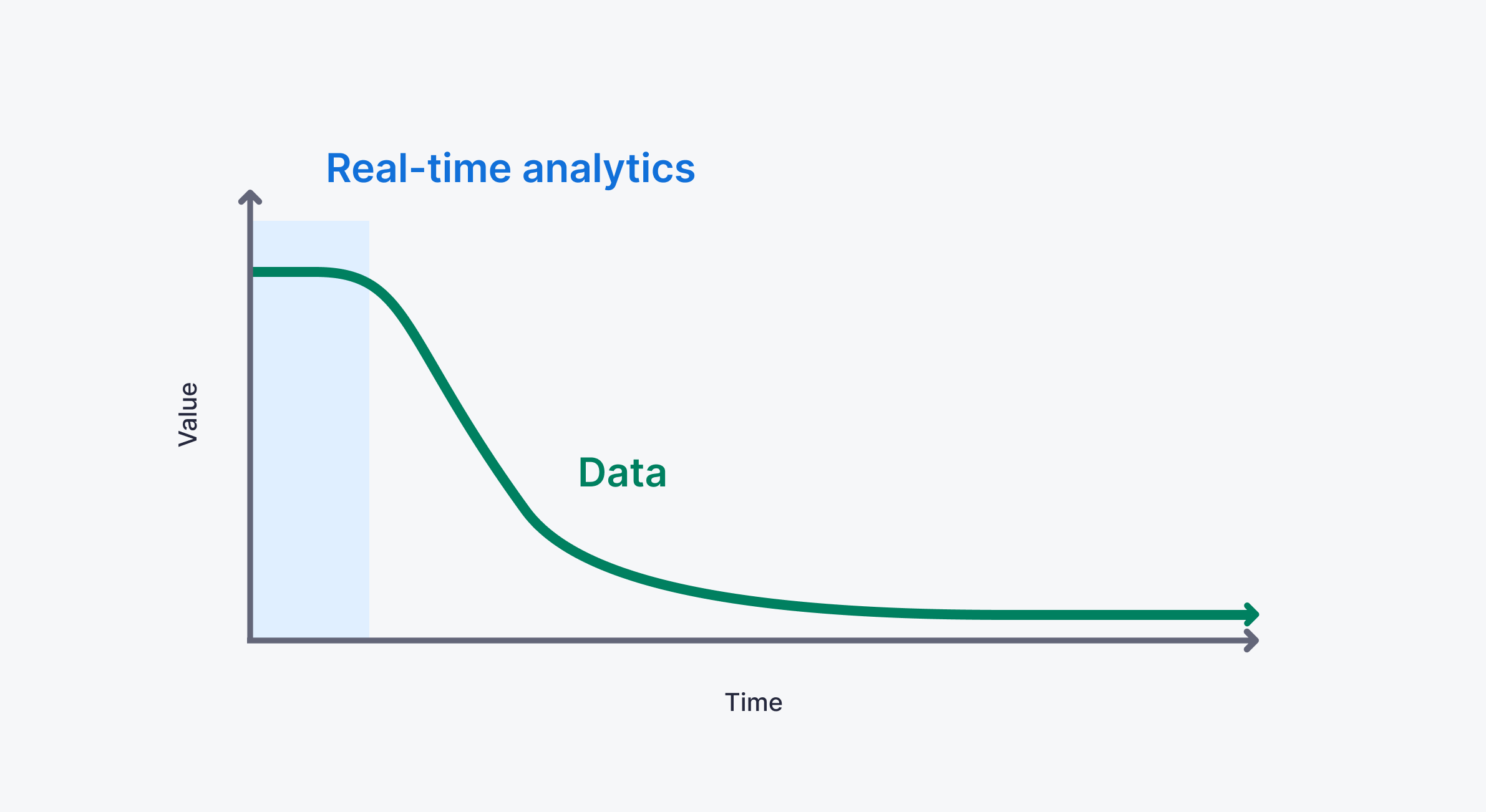
The goal of real-time data ingestion is to make fresh data available to downstream consumers. The fresher the data, the more valuable it is, and real-time data ingestion serves to capture data at peak value so that real-time data pipelines maximize their benefit to the business and its customers.
While many believe that latency is the most important metric for real-time data ingestion, we often think about “freshness” as opposed to latency. Whereas latency measures how quickly you can access the data once it has already been ingested, “freshness” is how quickly that data is available to be accessed in the system where it is needed.
Since SQL is the lingua franca of data, let’s use some SQL to define what we mean by “freshness”. Assume you have some system that generates events, and those events are defined by a simple JSON schema:
Where timestamp represents the moment the data was generated. Using a simple SQL statement, you could roughly measure freshness as:
Real-time data ingestion deals with minimizing the difference between now() and timestamp. The smaller the difference, the fresher the data, and the more “real-time” the ingestion is.
As the critical first layer in a real-time data analytics system, real-time data ingestion “sets the tone” for how quickly you can gain insight or generate automation from data analysis. Put simply, not even the fastest caching layer or most inspired SQL optimizations can overcome stale data. A low-latency query does you no good if the data is days old.
Is real-time data ingestion different from event streaming?
Real-time data ingestion and event streaming are two sides of the same coin. Real-time data ingestion extends the power of event streaming as a part of event-driven architectures, propagating streaming events into downstream systems where the data can be stored, processed, analyzed, and accessed.
Event streaming represents the process of moving data in flight, using an event streaming platform such as Apache Kafka or some other message queue like Amazon Kinesis or Google Pub/Sub.
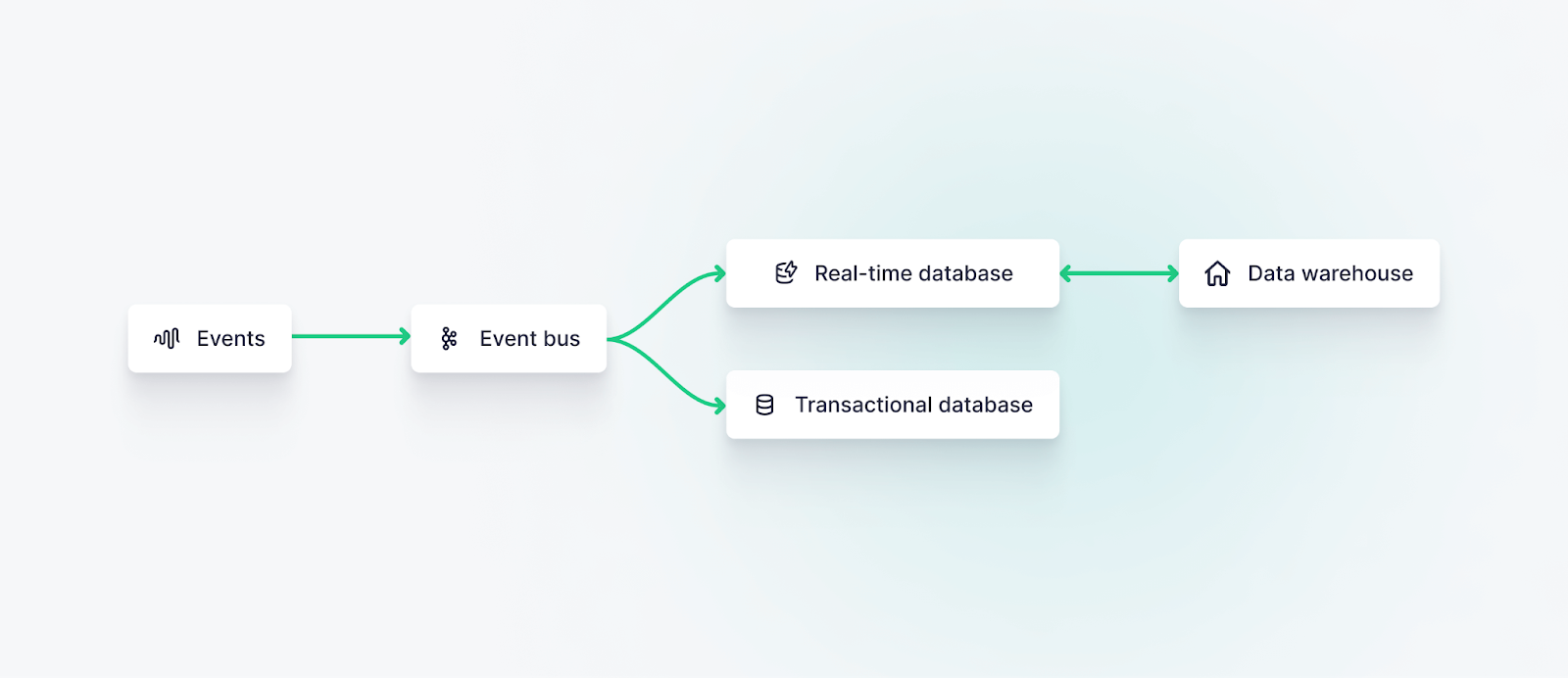
Real-time data ingestion, by extension, focuses on utilizing these systems to persist and store data in a real-time database or real-time data platform to facilitate storage, transformation, and access.
Critically, real-time data ingestion depends on a storage system that supports ingestion at streaming data scale, on the order of thousands or millions of events per second. This may be handled in near-real-time using “micro-batches”, but it is fundamentally different than batch processing methods which are designed to move data from one storage system to another, often utilizing ETL data flows.
The Importance of Real-Time Data Ingestion
But, why does real-time data ingestion matter? Consider a metaphor: You need to cross a busy street, but the cars you see in front of you have already passed by 15 minutes ago. The cars that are actually right in front of you are nowhere in sight. Meanwhile, everyone else can see in real-time and can safely maneuver to the other side.

You’re stuck waiting. Your competition has moved on.
This is what’s at stake for businesses operating today. As real-time data becomes more ubiquitous and its advantages more pronounced, those that don’t adopt these approaches risk getting left behind.
Real-time data ingestion, then, should be the first focus of any data engineering team at a modern organization. You should be asking and answering this question: how can you capture and store data from all your various data sources such that the data can be processed and accessed as quickly as possible to enable downstream, revenue-generating use cases?
Use cases where real-time ingestion matters
Let's take a closer look at some examples of real-time data ingestion in action to crystallize its importance.
Real-time data ingestion in retail
Imagine a retail company that wants to optimize the way it handles inventory. Using real-time data ingestion, the company captures data from its point-of-sale systems, e-commerce website, and supply chain management systems in real-time. At any moment, they know current stock levels across the globe and current customer demand for every product in stock. With real-time data ingestion, this information is barely seconds old.
From there, it takes some relatively simple arithmetic to completely revolutionize the way they manage inventory. They can make immediate decisions to restock popular items, adjust pricing strategies, personalize marketing campaigns based on individual customer preferences, or even use predictive analytics based on real-time data to determine when they’ll need to restock.
Retail companies must be able to move fast. All it takes is one Taylor Swift tweet endorsing your new lip gloss, and you’re inundated with sales. With real-time data ingestion, you can quickly identify the trend, analyze the underlying factors driving the demand, and take immediate action.
By leveraging real-time data ingestion, retail companies stay agile and responsive to market demands, which means less churn, higher conversion rates, and larger average order values.
Real-time data ingestion in financial services
Consider the financial services industry, where billions of dollars exchange hands every second. Real-time fraud detection and management become paramount to risk avoidance. Remember that fraud detection must occur in the time it takes for a purchase to be approved at a point of sale. Fraudulent transactions must be blocked quickly, but perhaps more importantly, non-fraudulent transactions must go through without the consumer missing a beat.
Financial institutions must be able to capture transactions within milliseconds of their initiation to be able to operate this way. None of this is possible without real-time data ingestion.
Real-time data ingestion in transportation
What if you’re managing logistics for a global airline serving millions of passengers - and their luggage - every single day? You need to know precisely where that luggage is, and where it needs to be, within seconds.
Airline CEOs famously say that the most critical strategy for any airline is to “get butts in seats, and seats in the air.” To do so demands tight schedules and incredibly precise logistics. Every second matters as planes, crew, customers, and luggage traverse skies and terminals en route to their final destinations.
Paired with vast networks of IoT sensors, real-time data ingestion allows airlines and other transportation services to keep track of their assets, their customers, and their customers’ assets in real-time, avoiding costly delays and customer dissatisfaction.
The Real-Time Data Ingestion process
As a reminder, the goal of real-time data ingestion is to capture information as soon as it is generated and deliver it as quickly as possible into a downstream system where it can be used asynchronously.
Real-time data ingestion, then, begins with generating data from events and ends with storing that data (either raw or transformed) in a database, data warehouse, or data lake where it can be further processed and queried as a part of user-facing analytics, data science workloads, machine learning systems, or real-time visualizations.
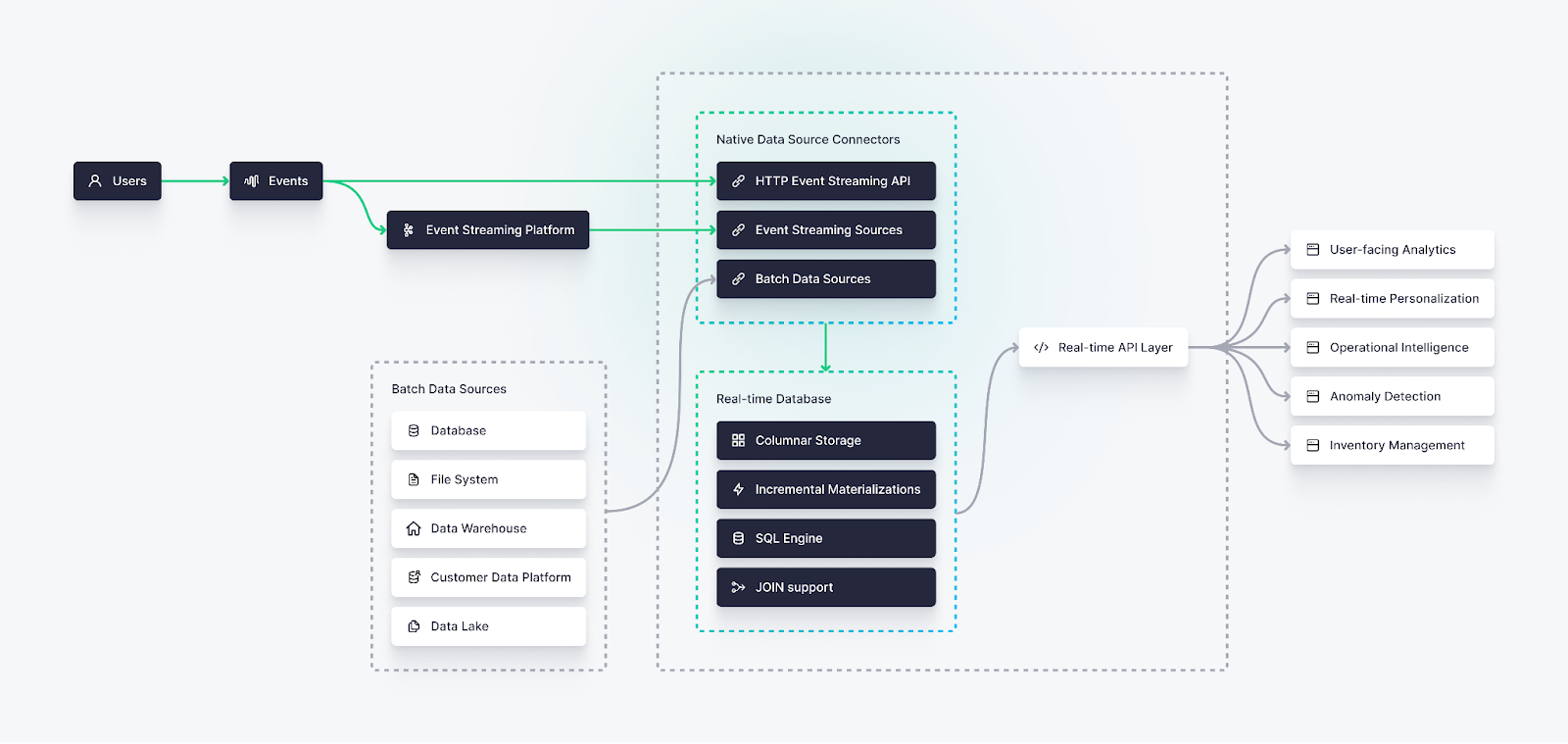
Event data generation
At the front end of the stack, you must generate event data streams as soon as the actual event occurs. Whether from IoT devices, social media apps, or other various sources, data must be generated and put in motion. This pattern, described by event-driven architectures, can be accomplished in a few ways:
- By modifying the application or service API to generate events before (or at the same time) that data is written to the application database
- Using real-time change data capture (CDC) to monitor the application database for recently generated data
- Using serverless functions (such as Lambdas) that are triggered by upstream processes.
Event streaming
Regardless of how it is created, real-time data is often placed on an event streaming platform or message queue immediately after it is generated.
Apache Kafka is the most popular open source event streaming platform, and its ecosystem includes many open and proprietary variants of the fundamental Kafka API.
Event streaming platforms are the transport mechanism for real-time data ingestion, and they often interface nicely with stream processing engines, real-time databases, and other downstream data systems through a variety of first-party or open source connectors.
Writing events to a database
Since many real-time analytics use cases are designed to serve asynchronous requests from many concurrent users, real-time data ingestion typically terminates in writing event streams to a database.
A real-time database that can handle high write throughput, like the open source ClickHouse, is often chosen here, as it can handle a high rate of ingestion at scale. These databases often have the added advantage of offering an SQL interface to query and expose the data.
As an extension, these databases might support incremental real-time materialized views, whereby the database management system can process data and perform filtered aggregates and other transformations at ingestion time.
Real-time Data Ingestion Tools and Technologies
Now that we understand the process of real-time data ingestion, let's explore some of the tools and technologies that you can use to achieve them.
Event Generation and Change Data Capture
Change data capture (CDC) tools are important in real-time data ingestion when the backend or API can’t feasibly be changed. Here are some popular change data capture tools that work for real-time data ingestion workflows:
Debezium
Debezium is a popular open source change data capture framework, and many have built upon it. It supports a wide variety of database connectors for CDC, from MongoDB to Postgres to MySQL and more.
Striim
Striim is another solid change data capture candidate, although its functionality is not only limited to change data capture.
Tinybird
Tinybird can be used for analytics on real-time change data capture streams. It is a real-time data platform that incorporates real-time data ingestion, real-time data processing, and real-time API generation in a single platform. Its Events API can be used as an alternative to CDC to send high volumes of event streams directly from application code into its native real-time database with a simple HTTP request.
Event Streaming and Message Queues
After data is generated, it’s moved to an event streaming platform or message queue. The following tools are popular for this purpose.
Apache Kafka
Kafka is a distributed streaming platform that allows businesses to publish and subscribe to streams of records in real time. It provides high-throughput, fault-tolerant messaging, making it ideal for large-scale data ingestion and processing.
Amazon Kinesis
Kinesis is a fully managed service by Amazon Web Services (AWS) that enables real-time data streaming and processing. It can handle massive data volumes and offers easy integration with other AWS services, making it a popular choice among businesses.
Google Cloud Pub/Sub
Pub/Sub is a messaging service provided by Google Cloud Platform (GCP) that allows businesses to send and receive real-time messages. It offers reliable and scalable message delivery, making it suitable for real-time data ingestion and event-driven architectures.
Azure Event Hubs
Event Hubs is a cloud-based event ingestion service provided by Microsoft Azure. It can handle millions of events per second, making it a robust choice for real-time data ingestion and analytics.
Real-time Databases and Data Platforms
The final stage of real-time data ingestion is to write event streams into a database where it can be later processed and accessed on demand. Here are some popular real-time databases and real-time data platforms.
ClickHouse
ClickHouse is an open-source, columnar database for real-time analytics over very large amounts of data. It offers high write and query performance, making it suitable for large-scale data processing. It also provides extensive SQL support, including support for complex joins and subqueries, which can be beneficial in real-time analytics scenarios that require more advanced querying capabilities. Originally designed to handle web clickstream data, ClickHouse adds many new features to its SQL dialect, making it especially useful for working with time-series and web event data streams.
Apache Pinot
Pinot is an open-source, distributed, and columnar database written in Java and designed specifically for real-time analytics on big data. Originally developed by LinkedIn, Pinot supports streaming data sources such as Kafka and complex data types, though its support for JOINs is limited.
Apache Druid
Druid is another open source column-oriented data store that’s optimized for time series data and low-latency queries. It offers a flexible ingestion model and support for approximate queries. Adding some complexity, Druid’s native query language is based on JSON, but it provides a custom SQL dialect on top.
Snowflake
Snowflake is a popular cloud data warehouse that is hosted on a cloud-agnostic managed public cloud. Snowflake is perfect for batch data processes and ETL workflows that support business intelligence, decision-making, reporting, and some data science functions, but it is not optimized for real-time analytics use cases.
In theory, you can use Snowflake’s Snowpipe streaming feature which can improve data freshness, but to bring freshness down to even a few seconds (slow for real-time use cases) this has proven to increase Snowflake costs even further.
Tinybird
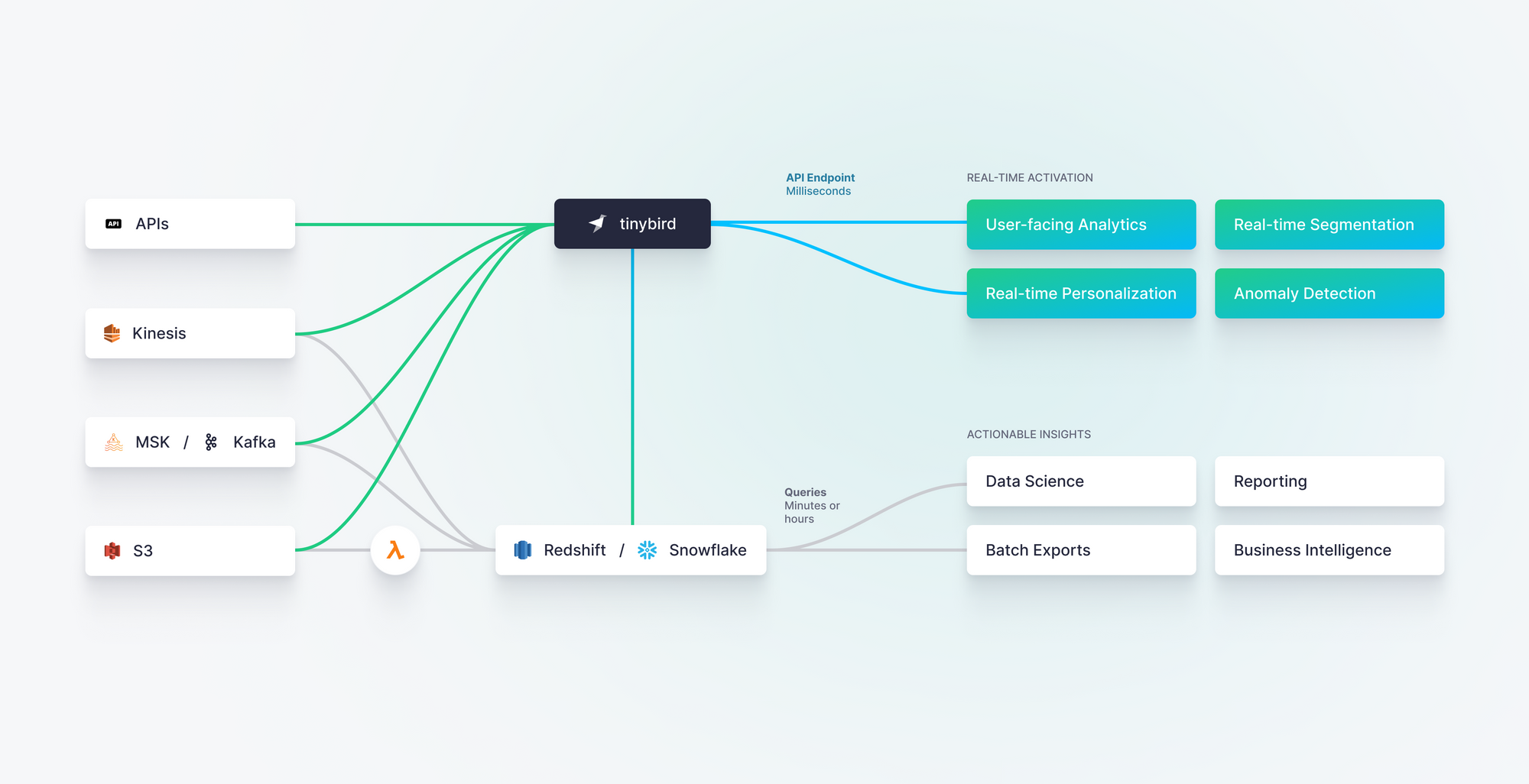
Tinybird is a real-time data platform built around ClickHouse, the world’s fastest OLAP database. With many native source connectors, Tinybird unifies batch and streaming data sources with wide JOIN support, enables real-time materialized views, and allows data teams to quickly publish real-time data pipelines as low-latency APIs. It is designed for real-time data ingestion, real-time data processing, real-time data integration, and real-time data access at scale.
Getting started with Real-Time Data Ingestion
Real-time data ingestion can be a game changer for motivated teams looking to build revenue-generating, real-time data pipelines at scale. However, for those comfortable with traditional batch processing techniques, real-time data ingestion can come with a learning curve.
Tinybird is an end-to-end real-time data platform for data and engineering teams. With Tinybird, you can not only ingest data from a wide variety of data sources in real time, but you can also process, transform, and publish real-time data products and empower your team to build things with data.
Tinybird might be the right place to start if you’re looking for reliable, scalable real-time data ingestion to power use cases like real-time personalization, user-facing analytics, usage-based billing, operational intelligence, and more.
You can try Tinybird for free with no time limit. If you get stuck along the way, join our active Slack community to ask questions about data source connectors, scalability, real-time data transformation techniques, and more.