Real-time streaming data architectures that scale
Data and engineering teams are turning to real-time data architectures to power revenue-generating data pipelines. This post provides a reference for building scalable streaming data architectures that can support multiple different use cases.


Real-time, streaming data has taken center stage in the world of data analytics and data processing. With the exponential growth of corporate data, data teams are facing the challenges that big data always told us it would pose: How do you handle and analyze petabytes of data (or more) as fast as possible (i.e. in milliseconds)?
This question has led to the emergence of real-time streaming data architectures that are designed to scale and meet the demands of the world’s most forward-thinking data-oriented companies and the differentiating use cases they are building.
In this blog, we present some guidelines for building real-time data architectures that scale, discuss the components of real-time data architectures, and offer some reference architectures to help guide your real-time data strategy.
In this blog, we present guidelines for building real-time data architectures, including 5 archetypes you can use to guide your real-time data strategy.
Understanding Real-Time Data
Before delving into the intricacies of real-time streaming data architectures, let’s stop to understand what exactly real-time data is. Real-time data refers to the continuous and simultaneous processing of data as it is generated.
Unlike batch processing, which involves collecting and processing data in intervals, real-time streaming data is processed as soon as it is received, allowing for immediate insights and actions to be taken.
Related: The definition of real-time data.
Definition of Real-Time Data
Real-time is characterized by its ability to provide up-to-the-second information and deliver it in a continuous and uninterrupted flow. This constant stream of data enables organizations to make informed decisions in real time, enhancing their responsiveness and agility in today's fast-paced digital landscape.
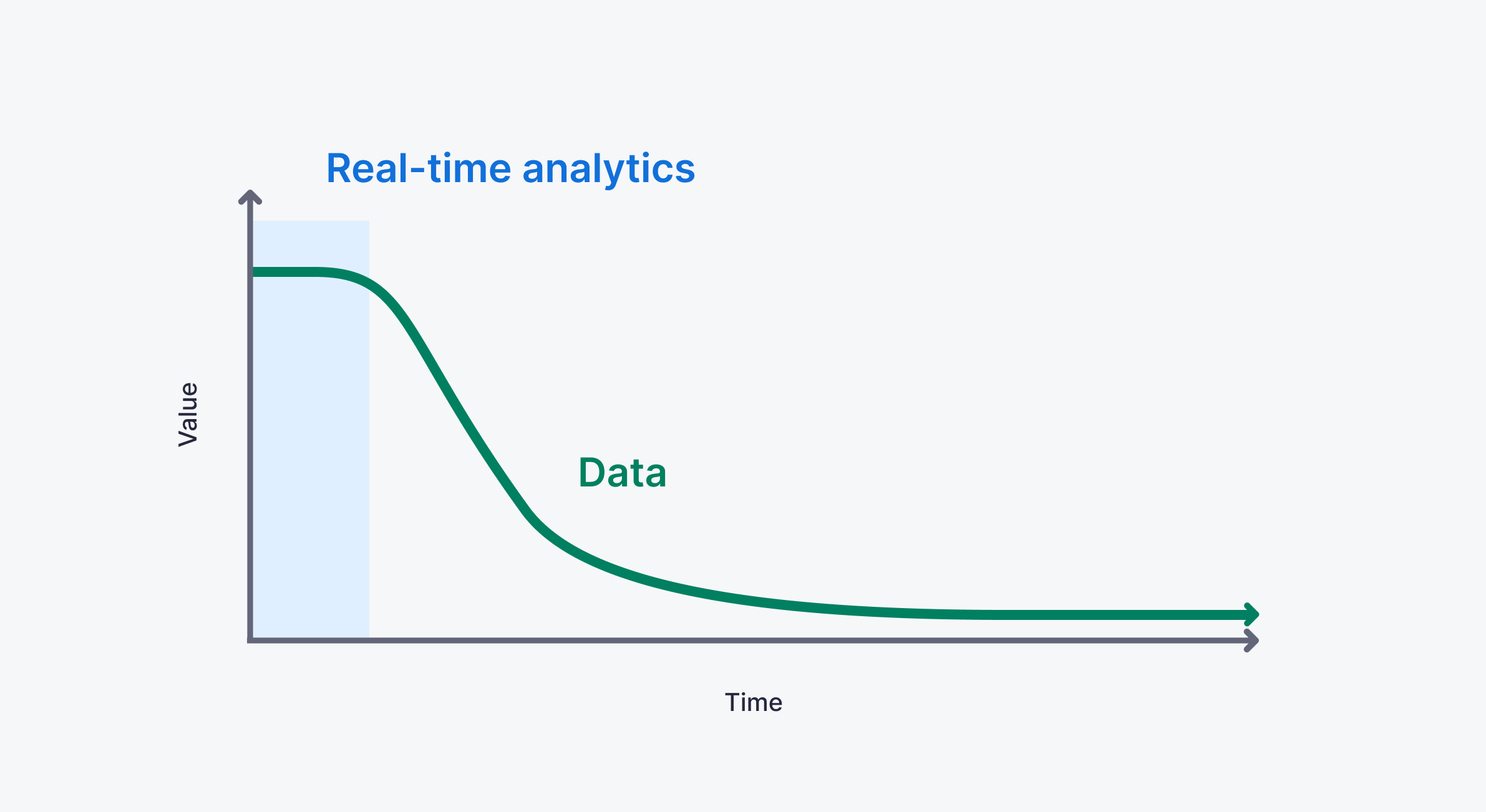
Now, there are some obvious caveats here. There’s no hard and fast rule for what “real-time” really means. One person’s real-time streaming data might be another person’s micro-batch. Rather than deal in absolutes, let’s focus on the pillars of real-time data: freshness, latency, and concurrency.
Put simply, real-time data follows these patterns:
- Freshness. It’s available for use as soon as it is generated. This is typically measured in milliseconds.
- Low-latency. Requests for real-time data can be served as soon as they are made. This is also measured in milliseconds. Compared to the non-deterministic latency of queries run on data warehouse job pools, real-time data queries should run on dedicated distributed infrastructure and return in milliseconds. This should hold true even when these queries do complex filtering, aggregation, or joins.
- High-concurrency. In contrast to business intelligence data, real-time data is often accessed by many concurrent users in user-facing applications. Rather than a few analysts or business users, real-time data is quickly accessed through many concurrent requests, often by external users. This could be thousands or even millions of concurrent users.
There's no quantitative threshold for data to be "real-time", but real time data architectures always prioritize data freshness, low-latency, and high-concurrency access.
Imagine a scenario where a financial institution is monitoring stock market data. With real-time data, market makers can analyze market trends as they happen and make timely - or even automated - investment decisions and capitalize on opportunities before their competitors. This level of immediacy and accuracy is only achievable through real-time analytics.
Key Components of Real-time Data Architectures
Real-time data architectures comprise several key components that work together to facilitate the seamless flow and processing of data. These components include data sources, streaming data platforms, stream processors, real-time analytics platforms, APIs, and downstream data consumers like user-facing apps and business intelligence.
Data Sources
As their name obviously implies, data sources are the source of data used in real-time data architectures. They can be any data-generating entity, such as sensors, applications, websites, or machines, that generate and transmit data to be processed in real-time.
For example, in the context of an Internet of Things (IoT) application, data sources can be a network of sensors deployed in a smart city. These sensors can collect various types of data, such as temperature, air quality, and traffic patterns. The data is then transmitted to an event streaming platform or message queue so that downstream consumers can utilize it in real time.
Furthermore, data producers can also include applications that generate real-time data, such as social media platforms, e-commerce sites, or financial systems. These applications generate a continuous stream of new data that needs to be processed and analyzed in real-time to extract valuable insights.
Streaming data is the lifeblood of any real-time architecture, but data from data lakes, data warehouses, or databases can also be used to enrich or hydrate real-time data streams.
Notably and by design, data sources in real-time architectures often don’t include application databases, cloud storage systems, or data warehouses as source data systems. In most cases, once data hits these systems, it has already lost freshness, disqualifying it from being used in a true real-time data system. Rather than use batch ETLs or change data capture to grab data from these systems, real-time data architectures prefer pureevent-driven architectures that place event data streams onto message queues as soon as the data is generated.
That said, data in static sources like data warehouses or data lakes can still be used to enrich event streams as a part of a real-time data architecture. For example, suppose an e-commerce site wants to provide personalized recommendations to online shoppers. They could analyze real-time streaming events data generated by shoppers during a session, and enrich it with product dimensions or historical cohort analysis stored in a data warehouse, creating a powerful real-time recommendation system.
Data sources play a pivotal role in the overall architecture, as the quality and reliability of the data they generate directly impact the accuracy and effectiveness of the subsequent data processing and analysis.
Event Streaming Platforms
Event streaming platforms are a cornerstone of real-time data architectures, providing the necessary infrastructure to enable real-time data ingestion and transportation of streaming data. They connect data sources to downstream consumers, ensure high availability, and can sometimes offer limited stream processing capabilities that can help data engineers transform data streams in flight.
The most popular event streaming platform is Apache Kafka. Kafka is a fault-tolerant, open source distributed streaming platform that provides a unified, high-throughput, low-latency platform for handling real-time data feeds. It allows data to be ingested from multiple sources, processed in real time, and consumed by various applications or systems.
Event streaming platforms like Apache Kafka are an integral part of any real-time streaming data architecture, reliably delivering event streams to real-time databases, stream processing engines, and other downstream consumers.
In addition to Kafka, there are other streaming data platforms available in the market, such as Confluent Cloud, Redpanda, Google Pub/Sub, and Amazon Kinesis. These platforms offer a range of features and capabilities to meet the diverse needs of organizations when it comes to streaming data.
Streaming Processing Engines and Streaming Analytics
Stream processing engines are often paired with event streaming platforms to apply transformations to data in flight. When compared to real-time analytics platforms, stream processing and streaming analytics tools generally process data over bounded time windows for near-real-time analysis and transformation, rather than persisting long-term storage of historical data into a real-time database.
A popular choice here is Apache Flink, an open source stateful stream processing engine. As with Kafka, Flink has many managed service offshoots like Decodable and Immerok (now part of Confluent).
Stream processing engines may or may not be a part of a real-time data architecture, depending on the capabilities of the database.
In addition to Flink, there’s Apache Spark Structured Streaming, which is useful for big data processing in real-time. Kafka Streams is another Kafka add-on that enables stream processing over streaming data pipelines. Cloud vendors like AWS or GCS also offer tools like Amazon Kinesis and Google Cloud Dataflow that can handle stream processing workloads in cloud-specific environments, which can provide cost efficiencies for cloud-native adherents.
Real-time Databases
Real-time databases offer a special class of capabilities as a part of a streaming data architecture. In effect, real-time databases act akin to a data warehouse like Snowflake, but optimize for real-time data processing rather than batch processing.
These databases are exceptionally efficient at storing time series data, which makes them perfect for real-time systems generating timestamped events data. Unlike stream processing engines, they are able to retain long histories of raw or aggregated data that can be utilized in real-time analysis.
Real-time databases like ClickHouse, Pinot, and Druid are optimized for high-frequency ingestion and low-latency analytics over streaming time series data.
Examples of open source databases include ClickHouse, Apache Pinot, and Apache Druid.
Real-time APIs
APIs are a relative newcomer in the event streaming data landscape, becoming a more popular way to expose real-time data pipelines to downstream consumers who are building user-facing applications and real-time dashboards.
APIs represent the streaming data divergence from the “Modern Data Stack” - as data engineers focus more heavily on enabling feature differentiation rather than business intelligence.
With the shift in focus to data-intensive applications that rely on real-time data, data teams want to build APIs that backend (and even frontend) developers can utilize for user-facing features. APIs can serve real-time analytics in a variety of data formats such as JSON, CSV, Parquet, etc.
As engineering teams shift their focus to building revenue-generating use cases, they rely on real-time data architectures that can expose their data pipelines to user-facing applications.
APIs are a specific implementation of a real-time publication layer for streaming data architectures when the downstream consumer is an application, but they represent a more general real-time analytics publication layer that exposes streaming transformations to downstream consumers.
Downstream Data Consumers
Data consumers are the end-users or applications that consume and act upon real-time streaming data. This can include business intelligence tools, real-time data visualizations, machine learning models, user-facing applications, or even real-time operations and automation systems.
For instance, a business intelligence tool can consume real-time streaming data from a real-time data platform and generate visualizations and reports that provide real-time insights into key performance indicators (KPIs).
Similarly, machine learning models can also consume real-time streaming data to make predictions and recommendations in real time. For example, a real-time fraud detection system can continuously analyze streaming transaction data to identify potential fraudulent activities and trigger alerts or take preventive actions.
Finally, downstream consumers may interact with streaming data APIs to power user-facing applications with real-time data features.
Data consumers are the last stop in extracting value from real-time streaming data. They leverage the insights derived from the continuous data stream to drive improvements in meaningful business metrics like customer experience, user retention, revenue generation, average order value, and more.
Scaling Challenges in Real-Time Streaming Data Architectures
While real-time data architectures can offer a huge lift to those who master them, they’re often tough to scale and maintain. In particular, data engineers will struggle with data volume, data velocity, and data variety when scaling real-time data pipelines.
Data Volume
The obvious hard part of building real-time streaming data architectures is dealing with big data. And I mean big data. The power of real-time architectures is their ability to merge both historical data sets and real-time event streams, meaning real-time systems should retain as much data as possible while using strategies like rollups to avoid unmitigated data growth.
Data Velocity
By nature, streaming data moves fast. Handling big data in real time requires architectures that can process and analyze the incoming data without any bottlenecks or delays. Data velocity and data volume go hand in hand. The faster streams are produced, the more data must be stored.
Streaming platforms like Apache Kafka largely solve many of the challenges with data velocity. But scaling and maintaining Apache Kafka is no cakewalk.
Streaming data platforms like Kafka largely solve many of the challenges related to data volume and velocity, but scaling and maintaining a large Kafka cluster is no cakewalk.
Data Variety
In addition to volume and velocity, data variety makes scaling real-time data hard. Often the source of streaming data is upstream applications or services built by developers, who may not care so much about downstream data quality. Streaming data can be structured, semi-structured, or unstructured, and may have myriad quality issues.
Consider a social media platform that emits real-time user interactions. A downstream analytics platform needs to process and analyze structured data such as user profiles, semi-structured data such as comments and likes, and unstructured data such as images and videos. To effectively handle and process different data formats, architectures need to be flexible and adaptable.
For example, application developers might choose MongoDB for it's ability to handle large volumes of unstructured data, but the qualities that make it good for developers can also make it challenging for data engineers building reliable real-time data pipelines using source data from MongoDB.
Strategies for Scaling Real-Time Streaming Data Architectures
To address the scaling challenges in real-time streaming data architectures, engineers can use these broad strategies to handle the increasing data volume, velocity, and variety.
Scaling Out
Scaling out involves distributing the processing of data across multiple nodes or servers. This horizontal scaling approach allows organizations to handle larger data volumes and higher data velocities by adding more processing power. By partitioning the data and load across multiple nodes, organizations can achieve better performance and handle the increasing demands of real-time data processing.
Scaling Up
Scaling up, on the other hand, involves increasing the processing power of individual nodes or servers. This vertical scaling approach enables organizations to handle larger data volumes and higher data velocities by upgrading their hardware or infrastructure. Scaling up can involve adding more CPU cores, memory, or storage to each node, allowing for more intensive data processing. Real-time data architectures often focus on optimizing real-time data processing, attempting to push as much compute as possible through a single core.
Partitioning
Partitioning involves dividing the data into smaller, more manageable subsets or partitions stored on distributed machines. This allows for parallel processing of the data, improving overall performance and scalability. By intelligently partitioning the data based on factors such as key values or data ranges, organizations can optimize the processing of real-time streaming data and ensure efficient utilization of resources.
Serverless Compute
Regardless of the tactic, scaling streaming data architectures is hard, especially if you’re bent on hosting your own storage and compute (or even managing cloud infrastructure). All of this requires dedicated resources that cost time and money.
Data and engineering teams that want to move quickly may turn to managed real-time data platforms with serverless compute models. These systems can speed up deployments and eliminate infrastructure headaches.
Recently, some data and engineering teams have started working with serverless architectures that scale elastically based on usage. Serverless architectures can be powerful for those that want to get to market quickly, as they abstract and eliminate infrastructure concerns.
Real-time data architectures for reference
So how do you actually approach real-time streaming data architectures? Below you’ll find a set of reference architectures for real-time data, each building on top of a basic archetype.
While purposefully generic, these real-time data architecture diagrams can help guide your real-time data strategy as you consider the tools and infrastructure you will need to achieve it.
Note that there are many different permutations to real-time architectures. How you approach it will depend on your specific real-time use cases and the demands of your downstream data consumers.
Here are 5 real-time data streaming architectures that build upon a common archetype.
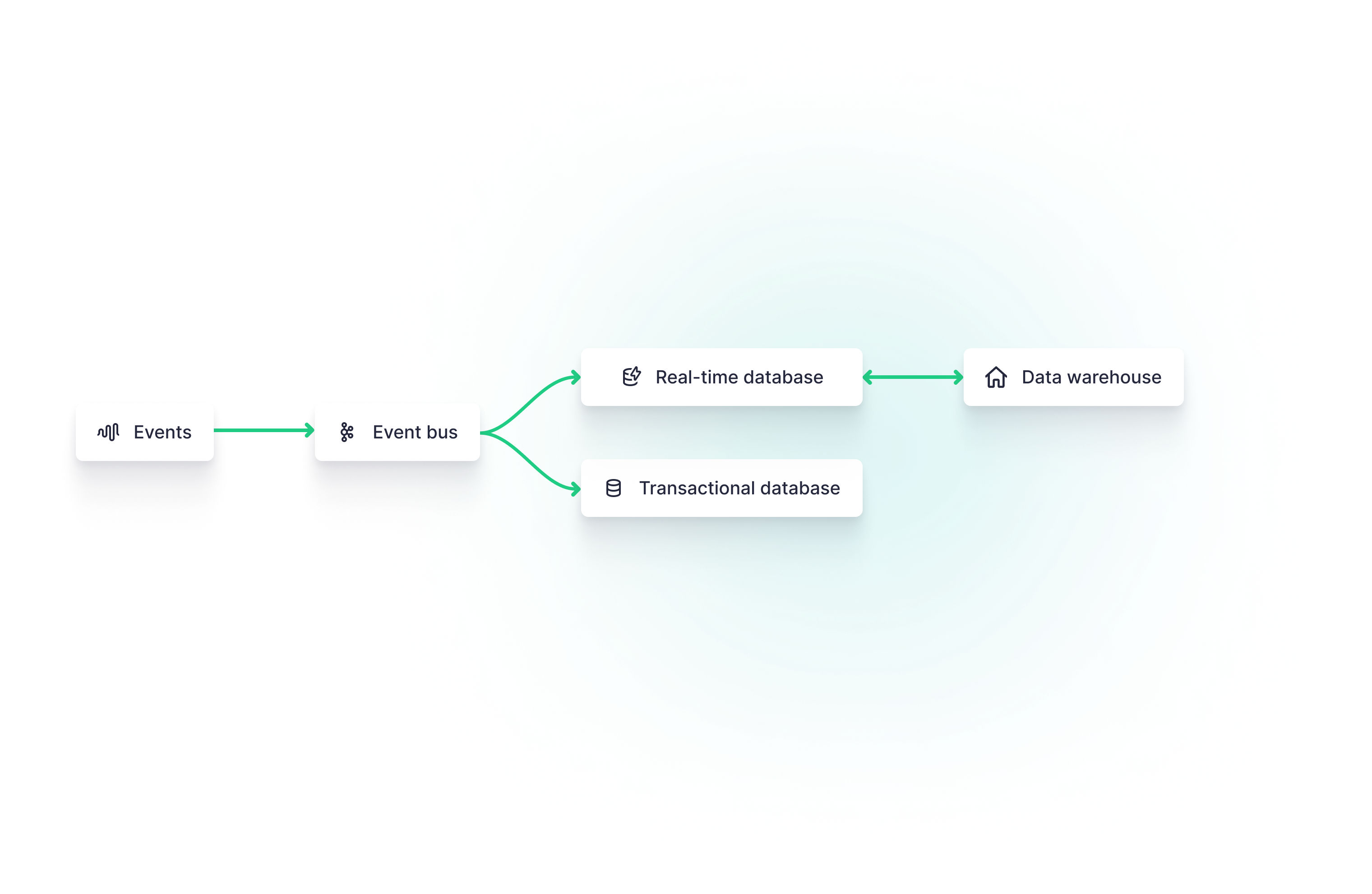
The Base Real-time Streaming Data Architecture
In its most basic form, a real-time data architecture is designed to store very fresh events data, captured through an event streaming platform, and make it available for use to downstream consumers, whether they have real-time needs or not.
Thus, the base architecture includes the standard event streaming platform/event bus to stream events data into both a transactional database, which may power general functionality for user-facing applications, a real-time database to power real-time analytics, and a long-term data warehouse to store large datasets for business intelligence.
Each subsequent architecture builds upon this real-time archetype.
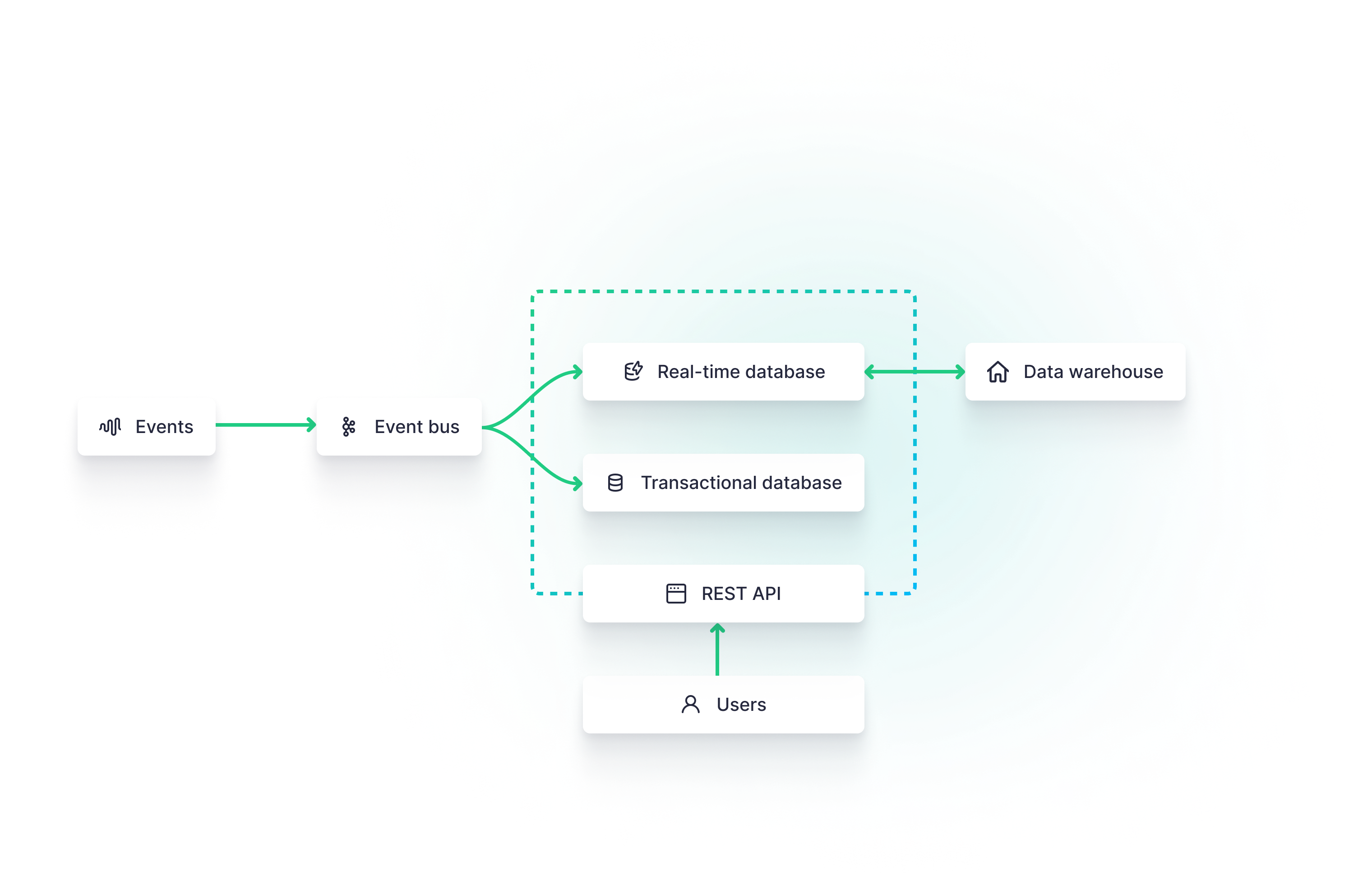
The User-Facing Analytics Application Architecture
One especially common use case for real-time data is user-facing analytics. In this scenario, software developers want to inject real-time data analytics into revenue-generating products as a value-added feature.
The most common approach is to create a REST API over both the real-time database and the transactional database. The transactional database continues to handle traditional OLTP workloads such as user metadata and auth management, while the real-time database supports OLAP workloads to power the user-facing analytics. The backend API is designed to interface with both OLAP and OLTP workloads for seamless customer experiences.
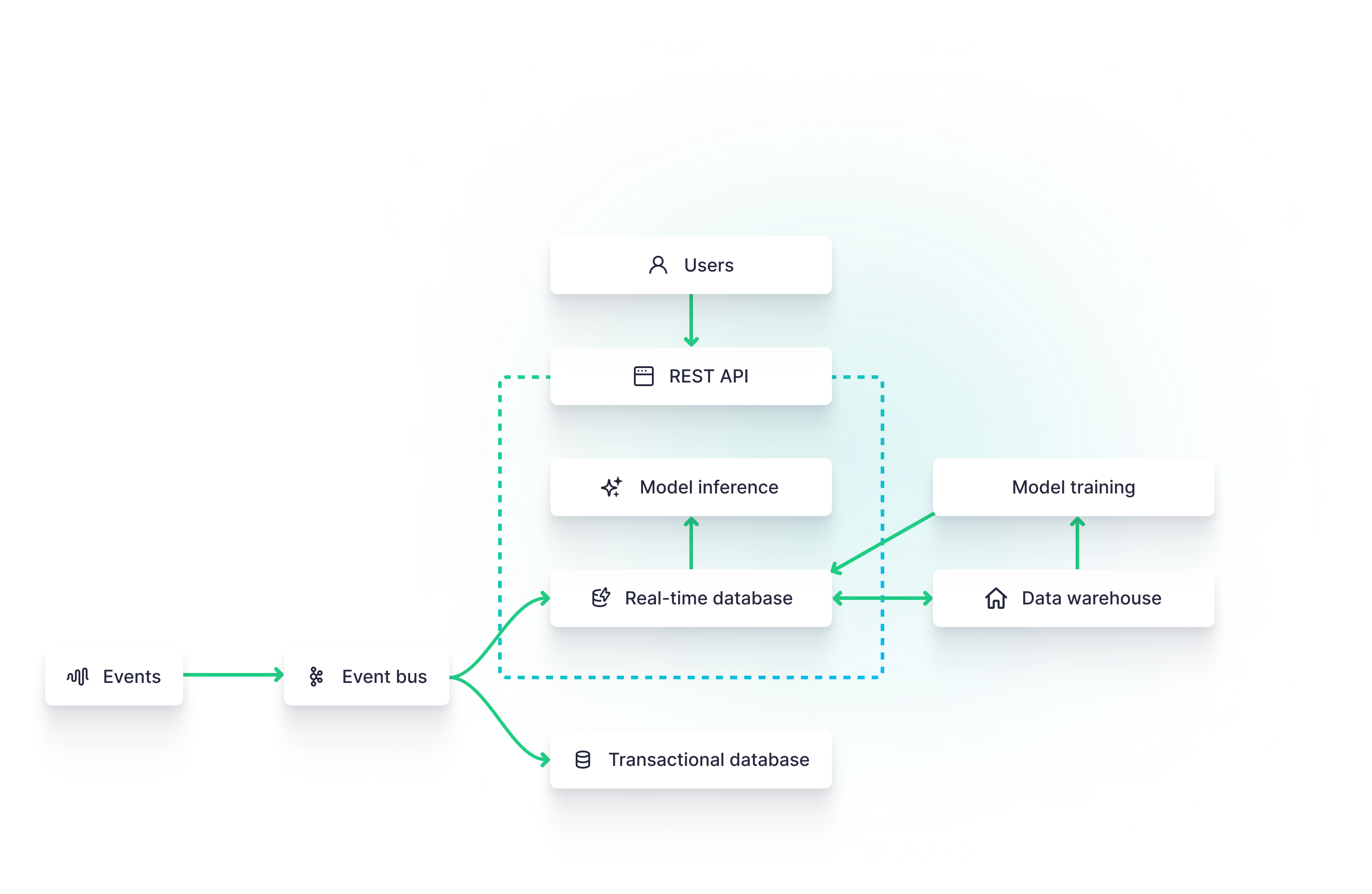
The Real-time Machine Learning Architecture
In many cases, real-time data is used to calculate features or vector embeddings to power machine learning models. In this architecture, the real-time database is used as an online feature store, calculating features on the fly to be used for model inference.
In parallel, a data warehouse (or data lake) supports long-term data storage for continuous machine learning model training.
This architecture supports common real-time data use cases like real-time personalization or real-time recommendation engines.
The Real-Time Operational Intelligence Architecture
Businesses commonly turn to data analytics for business intelligence using batch data processing. The same can be achieved with a real-time data architecture.
In this architecture, operations can be automated through APIs that interface with the real-time database. The real-time database stores and models critical metrics that determine how actions should be taken within user-facing or internal applications.
In parallel, business intelligence tools continue to perform long-running, higher-latency queries over the data warehouse.
One such example of this approach would be real-time fraud detection, where transactional data streams are modeled in the real-time database, informing automation (or perhaps ML models, see above) that identify potentially fraudulent transactions and halt them before they go through.
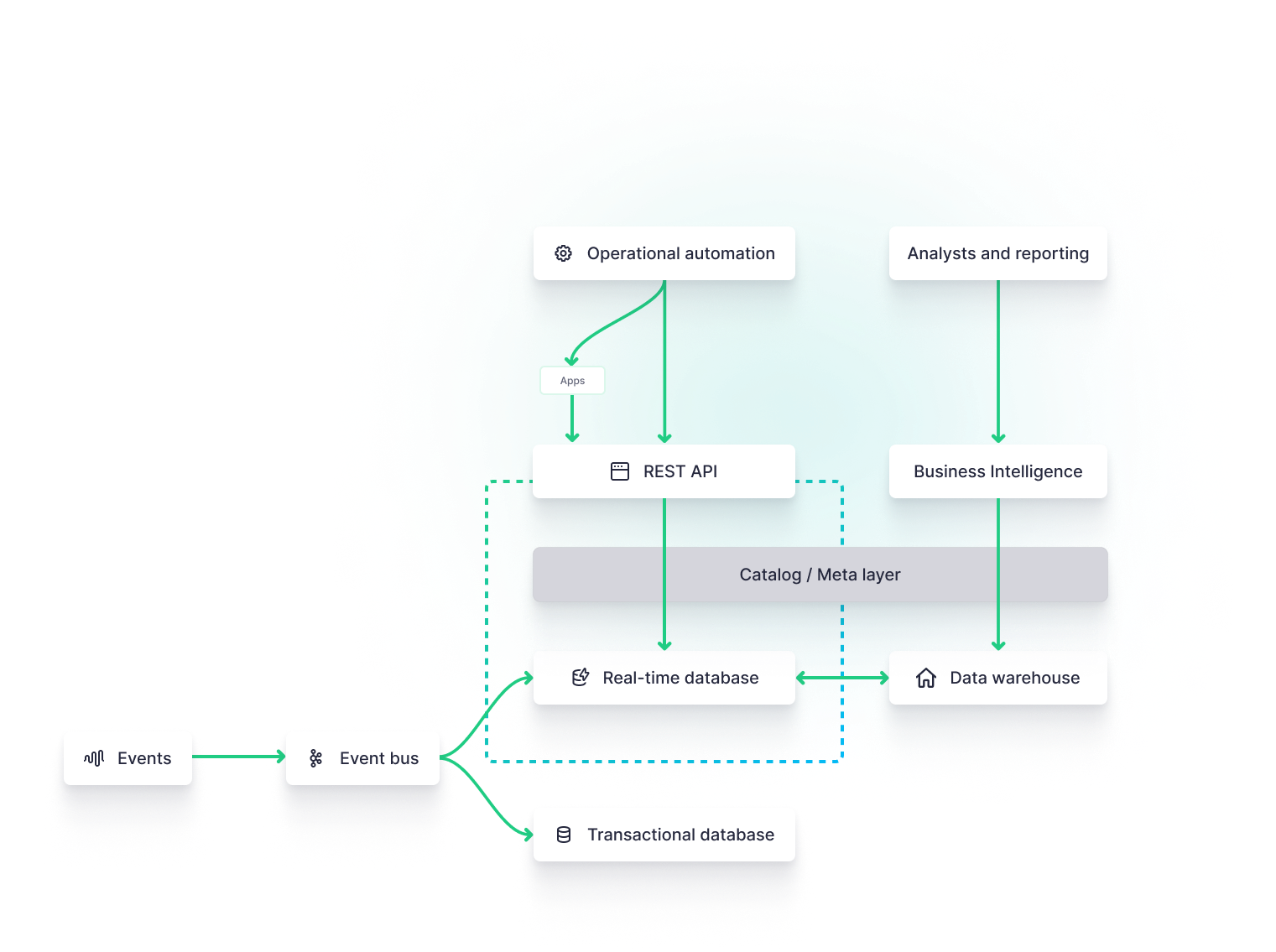
All of these architectures share common elements arrayed in different manners and integrated with different external tools and applications based on the use case.
Regardless of approach, real-time data architectures will include streaming events, an event bus, a real-time database, and some sort of API layer for external and downstream consumers to interact with the database.
The rise of real-time data platforms in streaming architectures
Technical handoffs and network latency are antagonists to real-time streaming architectures. As real-time tools become decoupled across distributed systems, increases in latency can impact the performance and value of real-time applications.
This challenge has given rise to integrated real-time data platforms. Real-time data platforms combine several components of the real-time streaming data architecture into a single tool.

Most commonly, real-time data platforms will minimize the technical handoffs required between the real-time database and the downstream application. For example, Tinybird is a real-time data platform that abstracts the API layer, optimizing performance and minimizing “glue code” by instantly publishing SQL models as high-concurrency, low-latency APIs.
Similarly, real-time data platforms often provide native, optimized data source integrators from both streaming and batch sources. In some cases, the real-time data platform may even include streaming functions. For example, Tinybird’s Events API functions as an HTTP streaming endpoint that can obviate the need for more complex streaming data tools like Kafka.
Building a real-time streaming data architecture
Looking to build a real-time data streaming architecture, but confused by all of the tools, concepts, frameworks, and infrastructure?
Your best bet is to start with a tightly-coupled real-time data platform like Tinybird. Tinybird makes it simple to unify both streaming data and batch data sources, develop real-time data pipelines with SQL, and publish your queries as low-latency APIs that empower downstream consumers to build revenue-generating products and features with data.
Tinybird is a real-time data platform that simplifies and accelerates adoption of real-time streaming data architectures.
To learn more about Tinybird, check out the documentation, sign up for free, or get in touch with our team. Or, if you're looking for general guidance on building real-time data architectures, join the Tinybird Slack community, which hosts a growing and active group of real-time data engineers and data-savvy developers who can help guide your real-time data strategy.