Build fast software with big data requirements
Somehow we got stuck on the idea that big data systems should be slow. We're making it fast.

Think about your day-to-day interaction with software:
- You write a prompt in ChatGPT (or similar) and the response is fast even if it's using billions of params.
- You search in Google and the response is fast, even though it's searching in billions of pages
- You play a videogame, and the gameplay is fast, even though it's rendering 60 frames per second, millions of pixels each.
But then:
- You build your dbt project and it takes 90 minutes to run.
- You build your javascript project and you need to wait 30 seconds for the build
- You want to know how many people signed up to your product last month and you need to wait for 10 seconds to see a number.
Someone once said that big data systems should be slow, and we've just come to accept that. The whole software industry has been building tooling, infrastructure, and SaaS around the idea that big data should be slow. The reality is that most "big data" use cases can be solved with less hardware (=less money) in real time.
We, as an industry, have become too accustomed to moving slowly when working with big data at scale, and that's a problem. We need to move faster.
So, we decided to shorten the feedback loop. When you build a real-time analytics API, the feedback loop should be ultrafast. You should be able to see the effect of a change in seconds. And I don't mean just checking the SQL, but the full backend: ingestion → transformation → API response.
When you adopt the mindset that “this has to be fast” from the early days of your product development, production projects tend to be fast, too.
Start using it by installing the new CLI:
curl https://tinybird.co | shIntroducing tb dev: Your Local Data Development Environment
tb dev is Tinybird's local development environment that gives you instant feedback on your data projects. Just as next dev transformed frontend development with hot reloading and instant feedback, tb dev brings that same fluid experience to your analytics backend.
With this simple command, you get:
- Instant feedback: See results in milliseconds, not minutes
- Real-time validation of your data schemas and transformations
- Validation of your SQL queries and API endpoints
- Hot reloading of your data fixtures
- A development loop so quick that you (or the LLM automation of your choice) can make decisions based on immediate output
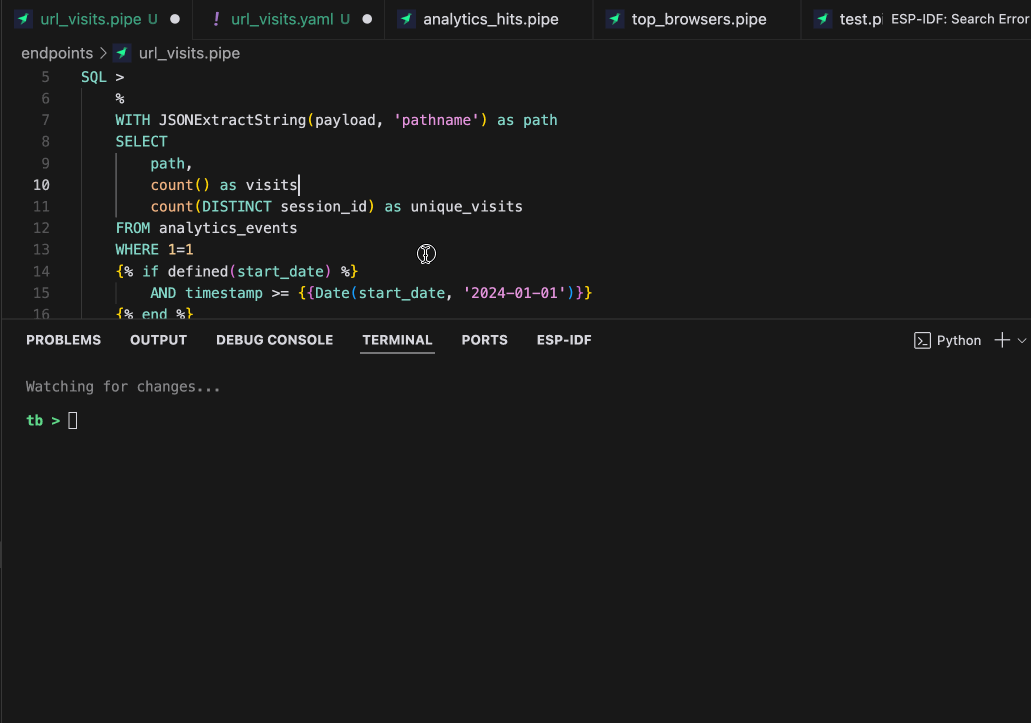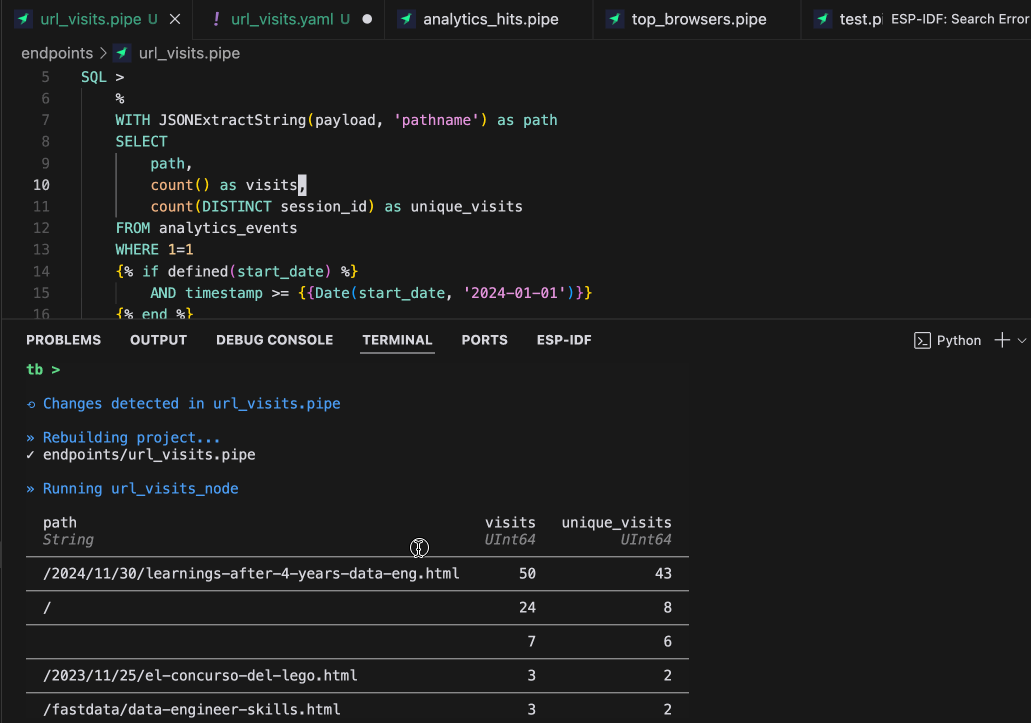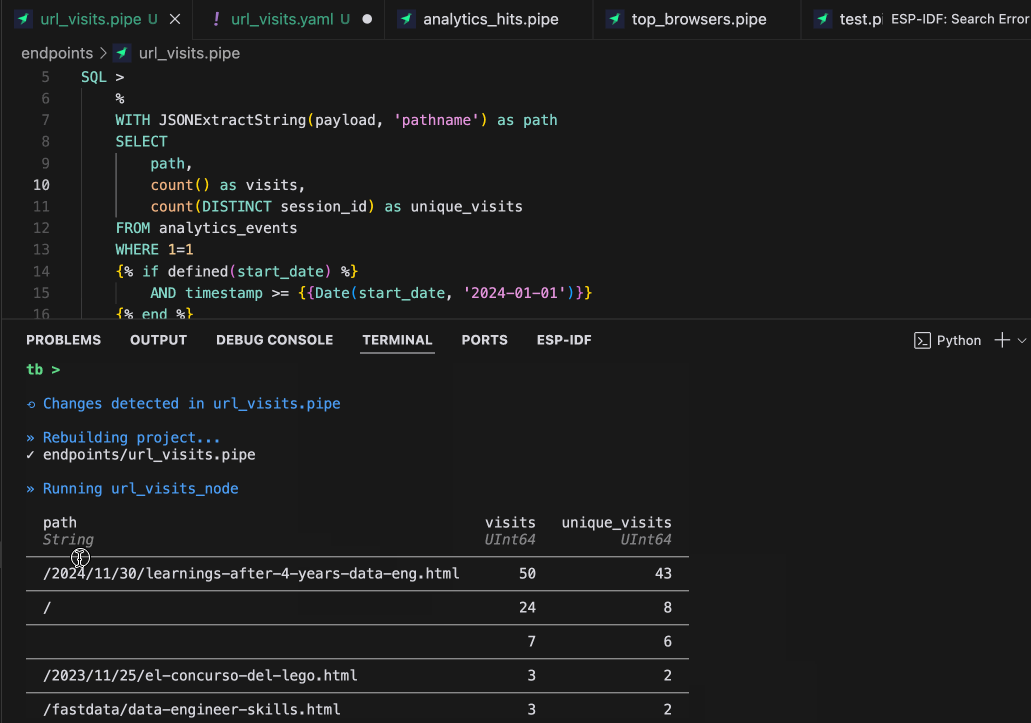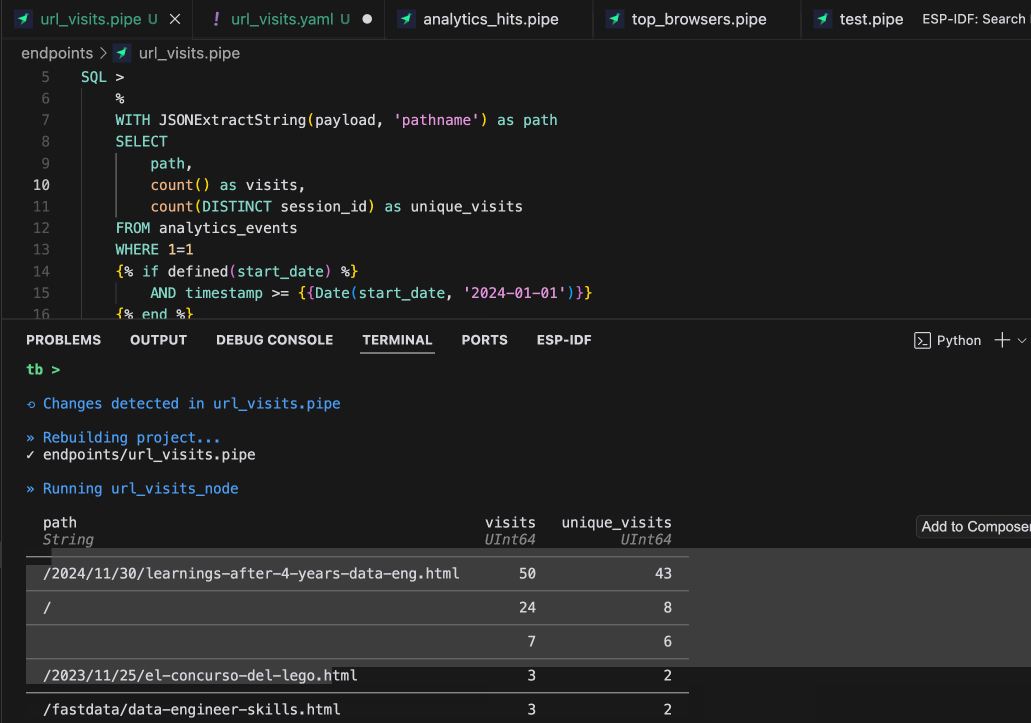
What can you do with tb dev?
When working on a typical software application, you usually work with the code, and sometimes you go to the database to check some things. But, when working on software with big data requirements (e.g. billions of rows of events), you spend less time in the SQL/code and a lot of time checking and debugging the data.
tb dev makes "debugging the data" a simple task by giving you immediate feedback on changes you make to your data pipelines, tested immediately against production (or production-like) data.
Here's what you can do with tb dev:
- Iterate on SQL queries instantly: Change a query, save the file, and see results immediately. You usually need to go to the data warehouse console, test, copy, and paste into the file, but no longer. You can test with local (mock) data or production data. If you modify the data, it loads it again, so you can change the data or the query and still get immediate feedback.
- Test API endpoints locally: Build and test your data APIs before deploying.
tb devdoesn't just build your queries, it builds your APIs and gives them real URLs (on localhost) that you can call from your application. When you deploy to prod it's as simple as swapping a CLI flag. - Work with sample data:
tb devuses mock data fixtures during the build, and you have a lot of control over how those fixtures get created (seetb mock). This helps you to test your pipelines without production data (which can contain sensitive info) - Debug with production data. If you do need to debug your APIs with production data, you can just append
--data-origin=production. This connects your APIs to production data while keeping your development environment isolated. It's the best of both worlds. - Debug in real-time: Identify and fix issues in your data transformations as you code.
… there are a few more handy features:
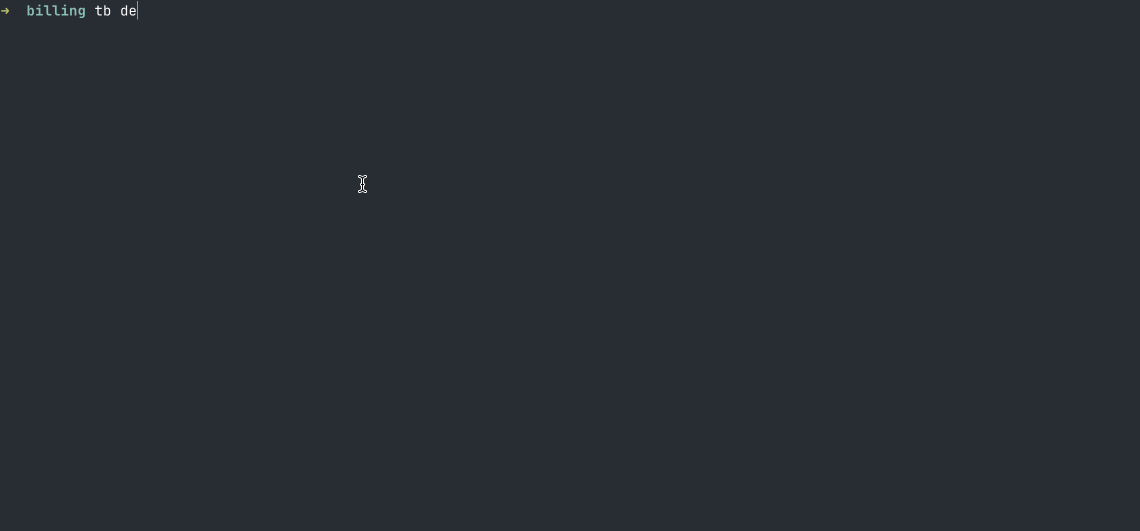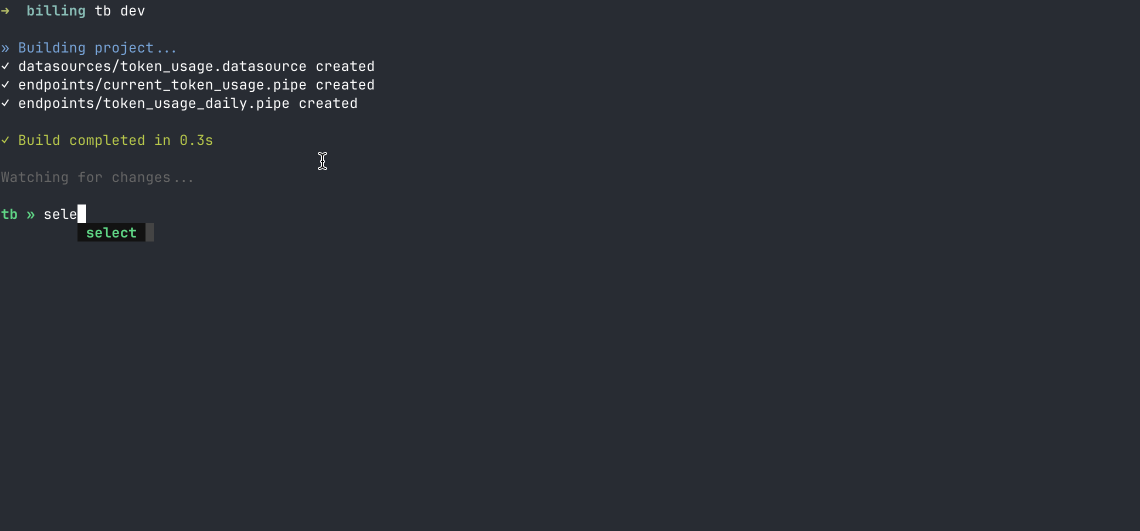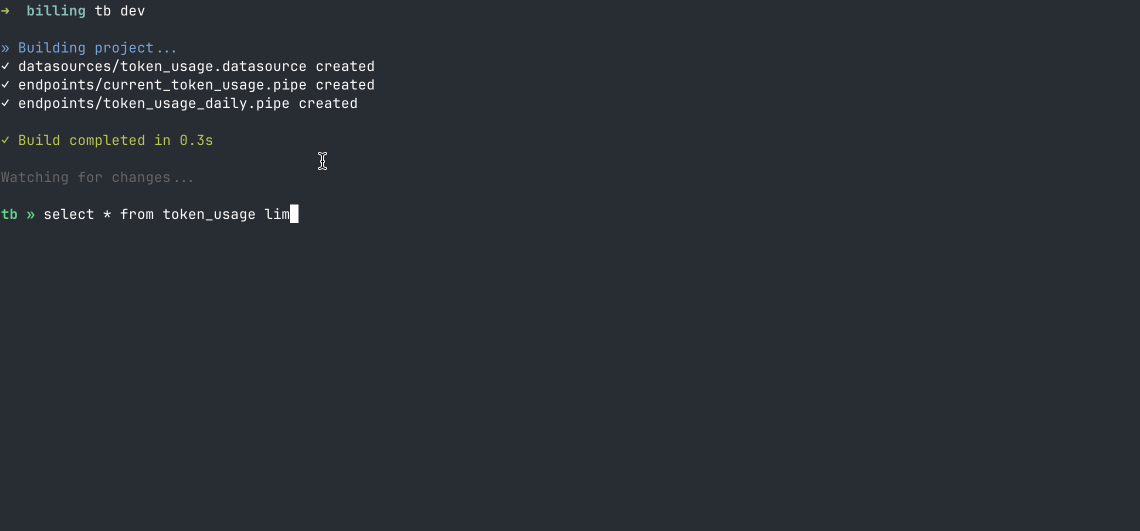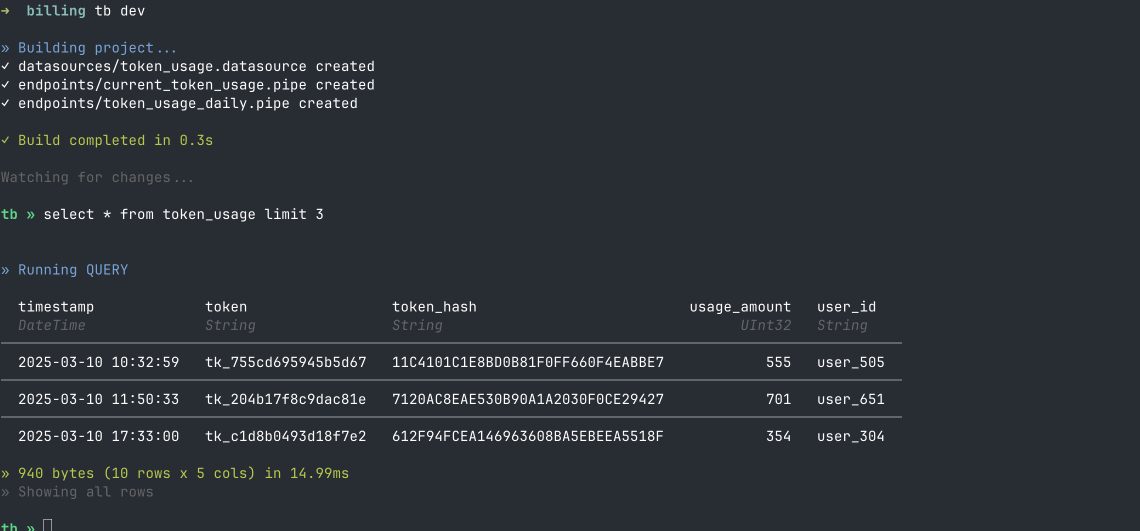
- It's an SQL console - you can just run SQL queries on your data from the CLI
- You can call any CLI command like
mock,create, and so on without having to leave the environment.
Other commands allow you to build and check your project before deploying it to production so you can use them in the CI/CD pipeline:
- tb build: Checks all the SQL and data sources, not just the syntax but also the relations between tables and pipes. This is the same thing tb dev runs under the hood.
- tb test run: Run the tests for each endpoint or pipe. tb dev will validate SQL, but running tests will validate your APIs return an expected response based on your application context.
- tb deploy --check: Check to see if you have a valid deployment. This compares your current build to your active deployment and checks if the new build can be promoted.
These commands are usually meant to be run in CI, but you can of course run them locally. I run tb build, tb test, and tb deploy –check all the time to validate my deployments before I ship to prod (stay tuned for more on deploying…)
Get started with tb dev
tb dev is the instant feedback loop when building your analytics backend. Every change, whether to your queries or your data, triggers a hot refresh so you can develop, test, and iterate locally alongside your frontend application.
You can get started with just a few commands: