Using Tinybird as a serverless online feature store
Machine learning can feel like a lot of hype, but feature stores are extraordinarily practical. In this post, I'll show you why Tinybird makes for an excellent online feature store for real-time inference and game-changing user experiences.


In recent history, machine learning has been a lot of bark and very little bite. The reality is that while machine learning models show tremendous promise for feature development at data-centric companies, the number of models shipped and scaled in production is vastly overshadowed by the piling heap of failed models and flopped features.
That said, there is hope. Every day, data scientists, data engineers, and machine learning engineers make progress on practical, grounded machine learning implementations that are buoyed by best practices and good architecture.
A common component of these implementations? Feature stores.
Feature stores create many efficiencies for data science teams by giving ML models access to reusable data features on which to train and make predictions. They have become a common component of mature MLOps model deployments across many companies and use cases.
Feature stores underpin repeatable, efficient, and scalable MLOps deployments.
But feature stores aren’t just the esoteric domains of AI researchers and senior data scientists. Now more than ever, the implications of feature stores affect broader data and engineering teams, including software developers and data engineers.
Consider the expectations of a modern customer. Users who interact with digital products expect the kinds of experiences that feature stores enable: real-time personalization, fraud and anomaly detection, and more.
If you’re a data engineer, you should be very interested in feature stores and the use cases they enable, even if your company’s data science and machine learning functions are still in diapers.
Even in organizations without mature machine learning and data science functions, feature stores can still be tremendously valuable.
In this blog post, I’ll quickly define a feature store, discuss online versus offline feature stores, and describe how Tinybird is being used as a serverless online feature store to create highly-differentiated user experiences.
Let’s dive in.
What is a Feature Store?
A feature store is a system or service that functions as the single source of truth for machine learning features. It stores, processes, and offers access to the calculated features of data records and can be used to develop, train, and run ML models.
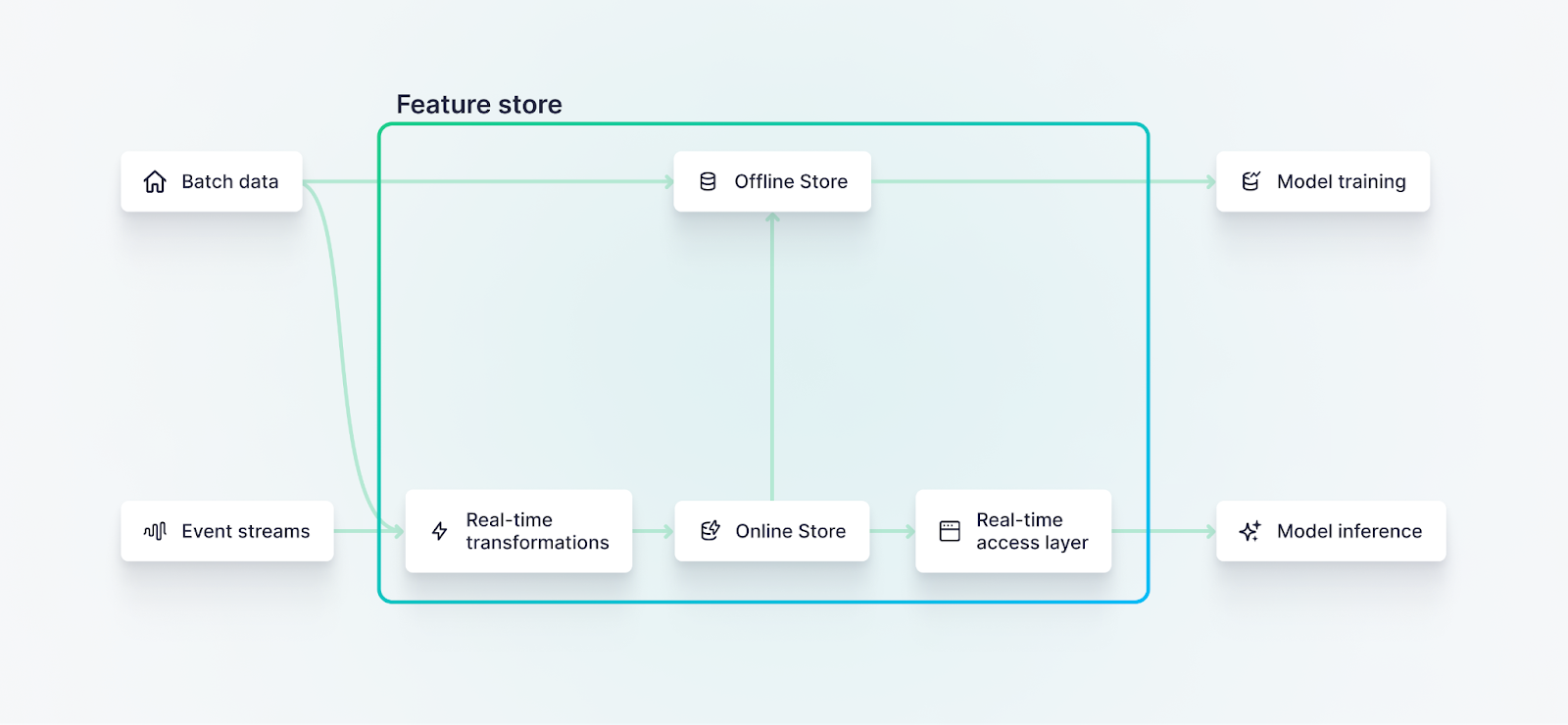
In this context, the term “feature” means a characteristic or property that can be used to describe the data. It is equivalent to a “column” in SQL or any other database schema.
Creating good, relevant features is critical to the performance of machine learning models.
Now, why should a data engineer care about feature stores?
- Efficiency and Reusability: If your company is now or ever starts doing machine learning, you’ll spend a lot of time on ‘feature engineering’ (i.e., preparing and selecting these columns). It's not uncommon for different teams or projects to end up creating similar features in disparate systems. A feature store prevents this kind of redundancy by enabling features to be shared and reused across teams and projects, just like reusable SQL views or stored procedures.
- Data Consistency: Without a feature store, there's a risk of training models on one set of features and then serving predictions with slightly different feature data. This can and will cause models to run inconsistently in production when they looked fine in development. A feature store ensures that ML models infer against the same dataset from which they were trained, similar to the role of a database in enforcing data integrity.
- Operational Efficiency: Managing feature data in a machine learning pipeline can involve a lot of complicated ETL tasks. It’s not uncommon to hear industry pundits joke that machine learning is actually 5% ML code and 95% glue code to get it into production. A feature store abstracts many of these “glue” tasks away, making them as easy to manage as database tables in a SQL environment.
- Monitoring and Versioning: A feature store typically comes with capabilities for monitoring drift in feature values and managing versions of features. If you've ever had to manually keep track of schema changes or manage SQL scripts for migrating data, you'll appreciate how a feature store can help automate these tasks.
- Scalability: Feature stores are designed to handle high-dimensional data and to scale horizontally, making them more efficient than traditional databases for certain types of machine learning workloads. You can think of a feature store as a highly specialized database system for machine learning applications.
Online vs offline feature stores
When you start investigating feature stores, you’ll encounter two different approaches: online feature stores and offline feature stores. They are not mutually exclusive and are often paired in effective MLOps deployments.
Just as an SQL database can be configured for transactional (OLTP) or analytical (OLAP) workloads, a feature store can have an "offline" store for training models and an "online" store for serving features to models in production.
Generally speaking, an “offline” feature store is optimized for processing bulk data operations efficiently, and is primarily used for training machine learning models.
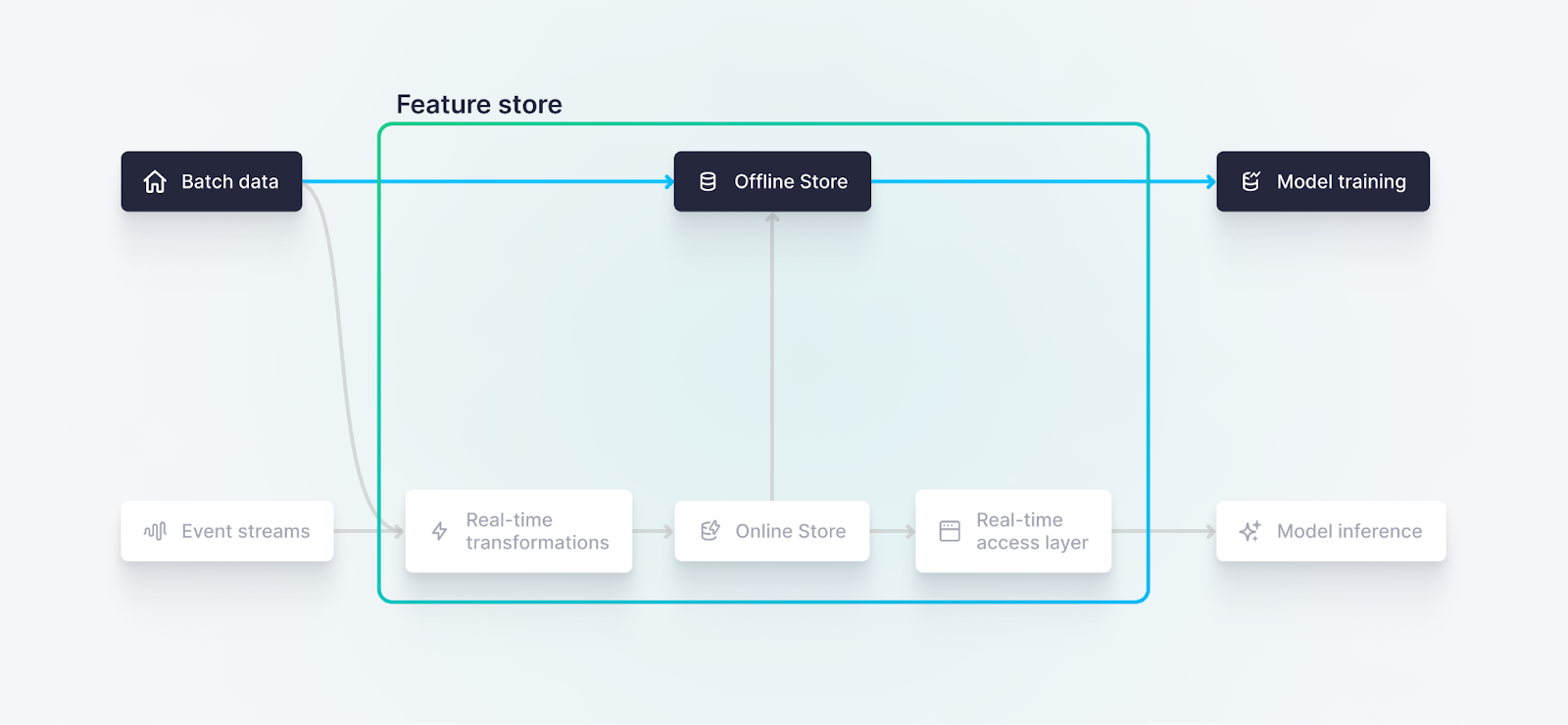
In many architectures, the offline store is housed in the cloud data warehouse and has access to a long history of records upon which the models are trained. Features may be calculated using a programming language such as Python or a query language such as SQL. Popular tools for developing offline features include Databricks, Snowflake, Amazon Sagemaker for AWS, Feast, and Tecton.
Offline feature stores are often housed in a cloud data warehouse, and hold a long history of feature computations, useful for continuous model training.
In contrast, an "online” feature store is optimized to serve specific data in real-time or near-real-time in order to drive machine learning model inference.
This is especially important when you are dealing with machine learning applications that implement prediction services in real time, such as fraud detection or recommendation systems.
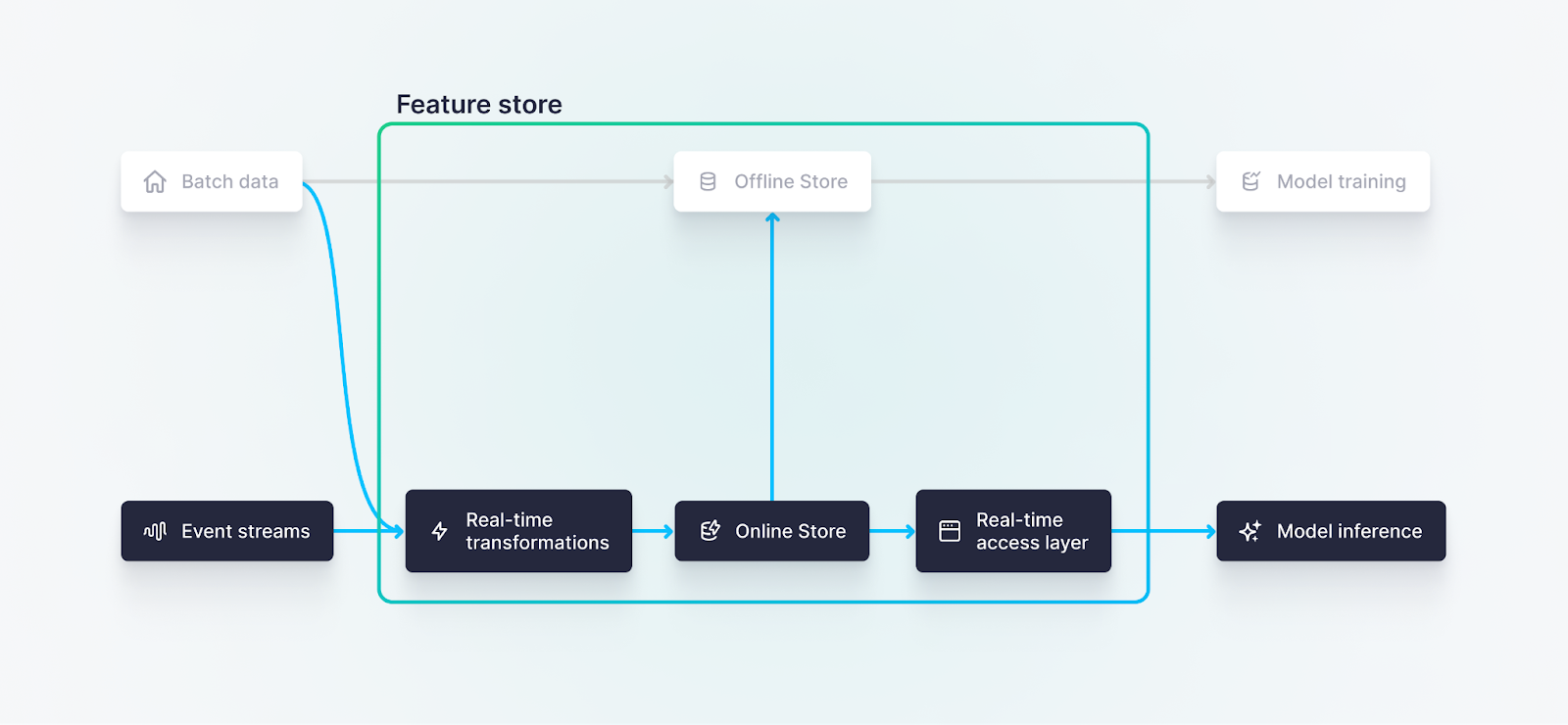
For example, when you’re shopping online and receiving personalized recommendations for what to add to your cart, there’s a decent chance that an online feature store is behind it.
In such applications, the model needs to make predictions based on the most recent data, such as all the items you’ve recently looked at, and it needs to do so very quickly to avoid degrading performance and user experience.
Online feature stores enable real-time feature computation and low-latency access for model inference on the most recent data.
Online feature stores for streaming data
In the context of streaming data from sources like Apache Kafka or Confluent Kafka, the online feature store is particularly relevant. Here's how it typically works:
- Data Ingestion: Real-time data is ingested from a streaming source like Kafka. This could be event data from users interacting with a website, sensor data from IoT devices, transaction data from a payment system, etc.
- Feature Computation: As the data streams in, the feature store performs the necessary transformations on the data to compute the features. These transformations are usually defined ahead of time as code and can be as simple as mathematical operations, on-the-fly enrichment from other sources, or as complex as windowed aggregate functions.
- Data Serving: The transformed features are then stored and served via the online feature store, which is optimized for low-latency, high-throughput read operations. When a machine learning model needs to make a prediction, it queries the online feature store to get the latest values of the features it needs.
- Data Sync: The online feature store is typically kept in sync with the offline feature store, albeit commonly with a Time To Live (TTL) on the storage of raw features. It is common to calculate the features in the online feature store, and then asynchronously export them to an offline feature store, which is optimized for batch operations and used to train machine learning models on this now historical data.
To summarize, an online feature store serves as a bridge between real-time data sources and machine learning models in production. Like an offline feature store, it holds calculated features that can be used to run ML models. However unlike offline feature stores, it calculates those features in real time and typically with a short TTL.
Choosing a database for an online feature store
As with any real-time analytics system, an online feature store demands a database that can keep up with both writes and reads in production.
Building real-time systems at scale comes with many challenges. Online feature stores are no exception. You need to be able to process thousands to millions of write operations simultaneously. You need to be able to handle a high number of concurrent reads. And you need to be able to balance the load on your infrastructure between writes and reads, as ingestion spikes can impact read performance, and vice versa.
Real-time databases are the obvious choice here, as they are designed for use cases with high-frequency write operations running simultaneously alongside high-concurrency, low-latency reads. Redis and DynamoDB are popular choices, but those aren’t your only (or even best) options in every case.
Redis and DynamoDB are popular real-time databases for online feature stores, but ClickHouse offers unique advantages.
As a high-performance real-time database, ClickHouse shines as an online feature store database. Thanks to its log-structured merge-tree approach, it can easily handle inserts of millions of rows per second. It also supports incremental rollups and materializations, which can become valuable performance boosters when calculating features on the fly. Furthermore, its column-oriented structure makes for fast retrieval of specific features when appropriately indexed.
All these things together, ClickHouse shows much promise as an online feature store.
That said, understanding and implementing ClickHouse is an undertaking in its own right, demanding resources that might not be available.
Tinybird: A serverless online feature store
Affectionately termed “ClickHouse++” by many data and engineering teams, Tinybird meets the necessary performance requirements with a serverless deployment model, ergonomic SQL development environment, and rapid API publication layer that makes it ideal as an online feature store.
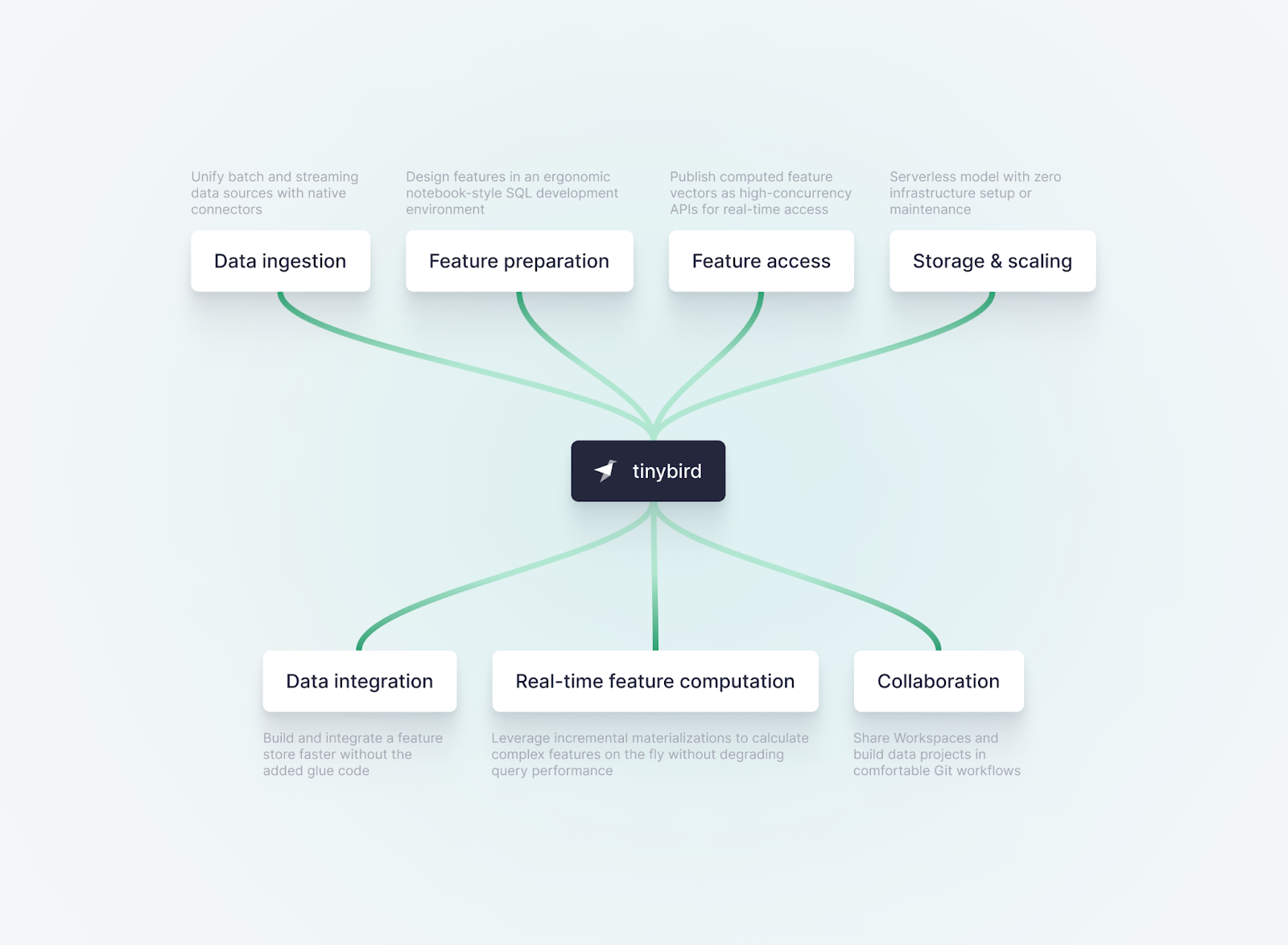
In particular, Tinybird makes the following aspects of online feature store development much simpler:
- Data Ingestion: Tinybird includes native data connectors that make it quite simple to unify data from both batch and streaming sources at petabyte scale and serve it at sub-second latency.
By simplifying real-time data ingestion from a wide variety of sources, Tinybird makes it much easier to develop features where data stream enrichment is critical for feature computation. - Feature Preparation: Tinybird offers an intuitive SQL development environment. Using a familiar and widely adopted language like SQL creates advantages related to team resources. Every data engineer and backend dev knows some level of SQL. The same can’t be said for Scala, Java, C, or Python.
With Tinybird, engineers can use SQL - and only SQL - to develop features in a familiar notebook interface. The flat learning curve and ergonomic development environment offered in Tinybird make feature preparation immensely approachable. - Feature Access: Tinybird makes it possible to instantly publish your calculated features as high-concurrency, low-latency APIs. This single capability massively simplifies online feature store development by giving machine learning models an instant low-latency access point for feature calculations.
By exposing the prepared features as REST API endpoints, Tinybird makes it trivial to integrate the feature store with any application or service that can make HTTP requests. This means that the models built by data scientists can retrieve the latest feature data in real time when making predictions without any additional glue code. - Feature Store Hosting and Scaling: As a serverless platform, Tinybird handles all the infrastructure management and scaling issues inherent in trying to host an online feature store. This means that data engineers and data scientists can focus more on the use cases and less on the operational aspects. It can also scale to handle massive amounts of data and high query loads.
- Data Integration: Tinybird is an integrated platform that combines data ingestion, data transformation, data storage, and data publication in one development interface.
A significant portion of a data scientist's time can be taken up with 'glue work' - the work of getting different systems to integrate, converting data formats, etc. By bringing the various components of an online feature store and providing a simplified interface to access them, Tinybird cuts down on this glue work, making the whole process of building and maintaining an online feature store more efficient. - Real-time Feature Computation: Leveraging ClickHouse's materialized views, Tinybird pre-calculates and automatically updates feature data upon ingestion. This shifts compute-intensive transformation operations away from query time and towards ingestion time, which means that ML models that access features in production can make their predictions much faster and much more cost-effectively thanks to reduced scan sizes.
How fast is “much faster”? We’re talking sub-second end-to-end latency and query responses in milliseconds, even over billions of ingested rows, and concurrency measured in thousands of queries per second. - Collaboration: Tinybird is built for cross-team collaboration, enhancing productivity for machine learning and data engineering teams. Shared “Workspaces” enable multiple users to collaboratively develop features using “Pipes”, an interface akin to Jupyter Notebooks but for SQL instead of Python.
Tinybird massively simplifies the development of online feature stores.
Teams can create point-in-time copies of “Data Sources” for consistent training scenarios, and share features securely with other workspaces for expanded experimentation.
Additionally, its token-based access control to API endpoints ensures secure data access and manipulation, and every endpoint comes with built-in observability, making it a comprehensive tool for collaborative machine learning workflows.
Tinybird vs Redis or DynamoDB
Considering all these things, Tinybird offers a unique advantage over Redis and DynamoDB.
Most feature store implementations using Redis or DynamoDB simply push static values from the offline store into these high-concurrency key-value lookup services. The features can be accessed quickly, but they’re still stale.
Tinybird, on the other hand, dynamically applies transformations at the time of ingestion. Redis and DynamoDB simply can’t achieve this without additional stream processing infrastructure.
Tinybird truly functions as a serverless online feature store-as-a-service, providing all the necessary functionality without any of the add-ons or glue code.
Online feature stores built with Tinybird
Many Tinybird customers are already creating highly performant online feature stores for a wide range of use cases in different industries. Here are three example implementations showcasing how Tinybird functions as an online feature store while easily integrated with streaming platforms like Confluent and batch-oriented platforms like Databricks.
Real-time personalization in fast fashion
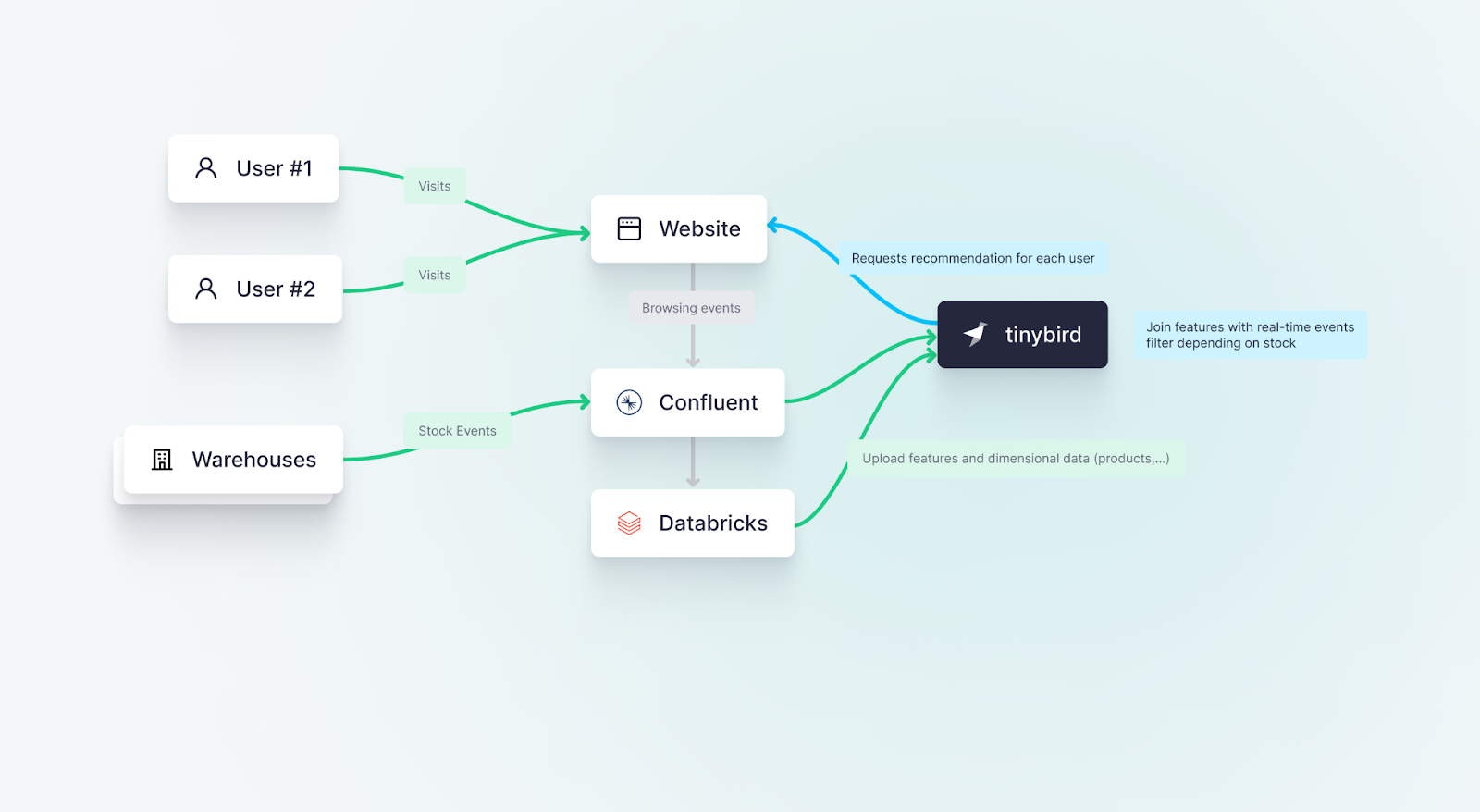
A global eCommerce fashion business successfully leverages both Tinybird and Databricks to optimize their recommendation algorithm and manage real-time stock inventory, enhancing customer experience and boosting conversion rates.
A global fast-fashion retailer uses Tinybird as a serverless online feature store to serve personalized checkout offers to eCommerce site visitors based on their most recent browsing behavior and up-to-date stock inventory data.
The core process can be broken down into the following stages:
- Data Aggregation with Tinybird: User traffic data on the eCommerce website, including product views, cart activities, and completed sales, is captured into Confluent and forwarded to Tinybird for real-time aggregations. This data provides a live snapshot of customer behavior and interactions, serving as a rich source of information for various analytics and machine learning tasks.
- Model Training with Databricks: Meanwhile, historical data stored in Databricks is used to train machine learning models for recommendation algorithms. Databricks’ large-scale data lake capabilities and support for diverse data types make it an ideal platform for processing and analyzing large volumes of historical data needed for machine learning.
- Real-time Predictions with Tinybird: Once trained, the recommendation models are fed with real-time data from Tinybird's online feature store to make in-checkout offers to customers. These recommendations, based on the most up-to-date customer activities, increase conversion rates by offering customers what they're likely to want at the right moment.
- BONUS: Stock Inventory Management: In addition to feeding the recommendation system, one of the other use cases for Tinybird is maintaining an up-to-date view of the company's stock inventory. This enables the company to dynamically adjust the in-checkout offers based on current stock availability, ensuring that the products they recommend are actually available for sale.
This integrated system allows the eCommerce company to benefit from both real-time insights and in-depth historical analysis.
As the online feature store, Tinybird facilitates quick and responsive data processing, storage, and access, ideal for real-time recommendation and inventory updates.
As the offline feature store, Databricks provides comprehensive historical data analysis, enabling the creation of sophisticated machine learning models.
By effectively leveraging these platforms in their respective areas of strength, the eCommerce company can deliver timely, relevant, and fulfillable recommendations to its customers.
Personalized booking experiences in global hospitality
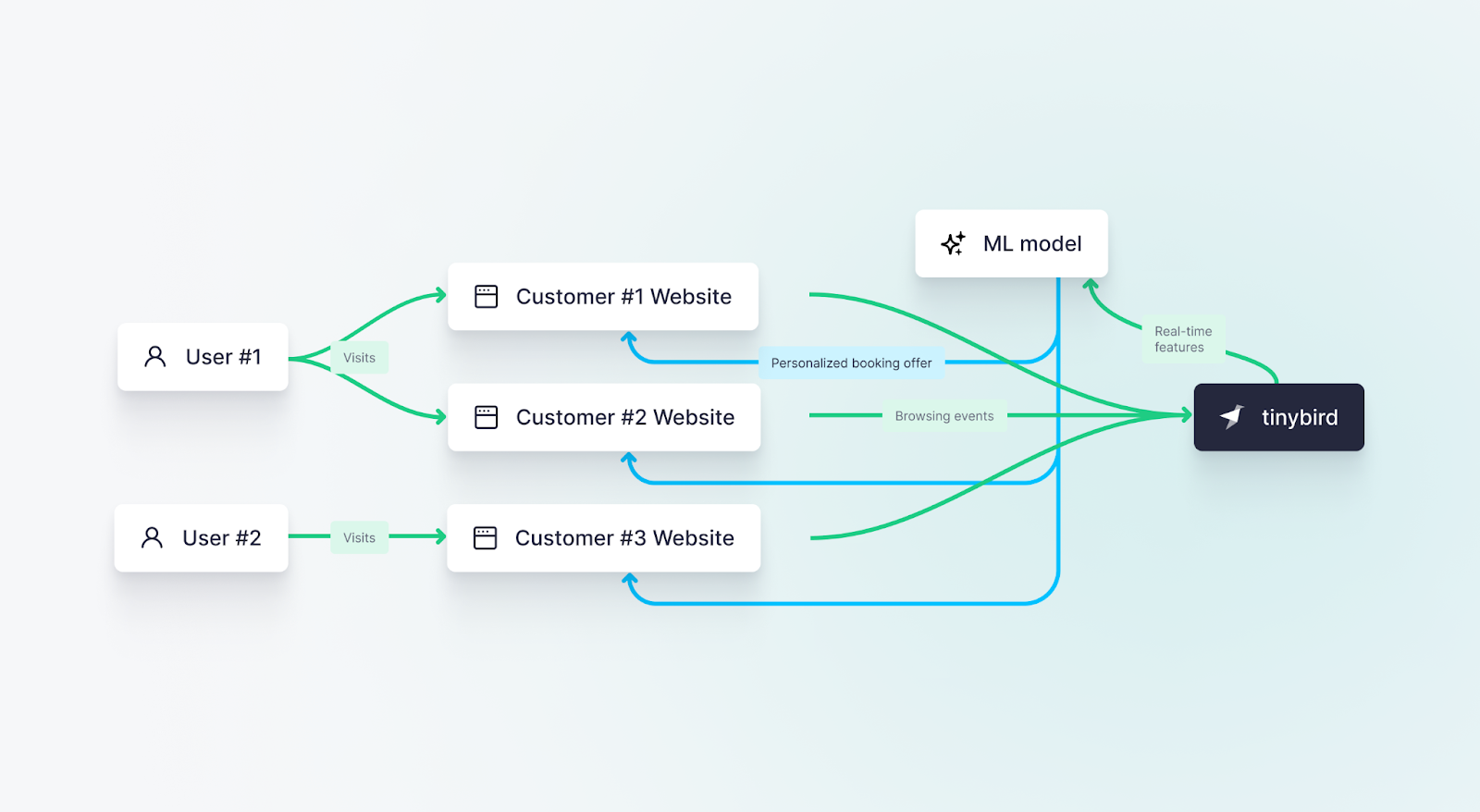
In this innovative application, a Travel Bookings Platform harnesses the power of Tinybird to optimize their client hotels' online offers and discounts, increasing bookings conversions through an enhanced understanding of customer buying habits.
A large hotel bookings platform uses Tinybird as a serverless online feature store to allow its customers to place customized booking offers during customer browsing sessions, leading to higher booking rates.
The process operates in several key stages:
- Real-time Data Aggregation with Tinybird: The Platform gathers user characteristic data across thousands of client hotel websites, and throws it all into Tinybird in real-time. This comprehensive data reflects a multitude of user journeys, encapsulating customer behaviors, preferences, and interactions across diverse contexts.
- Feeding the ML System: Tinybird maintains an up-to-date vector of transformations (the “features”) for every visitor, which is then accessed by the Platform’s ML model to serve an offer with a high likelihood of conversion during booking.
- Continuous Retraining of the ML System: Not only does the real-time data feed into the prediction-making process, but it also contributes to the ongoing retraining of the machine learning system. This means the system can adapt and evolve based on what is working and what isn't, ensuring its recommendations stay relevant and effective.
- Tinybird supports MLOps: Unlike the previous use case, where Tinybird directly serves the features and recommendations to the user-facing application, in this scenario Tinybird works to support the MLOps deployment by supplying the machine learning model with the real-time data it needs to make and continually improve its predictions.
This use case showcases another powerful way to use Tinybird as an online feature store. By capturing and feeding real-time data at massive scale into an ML system, it helps the Travel Bookings Platform provide their client hotels with actionable insights for optimizing their sales strategies.
Real-Time Sports Betting Analytics
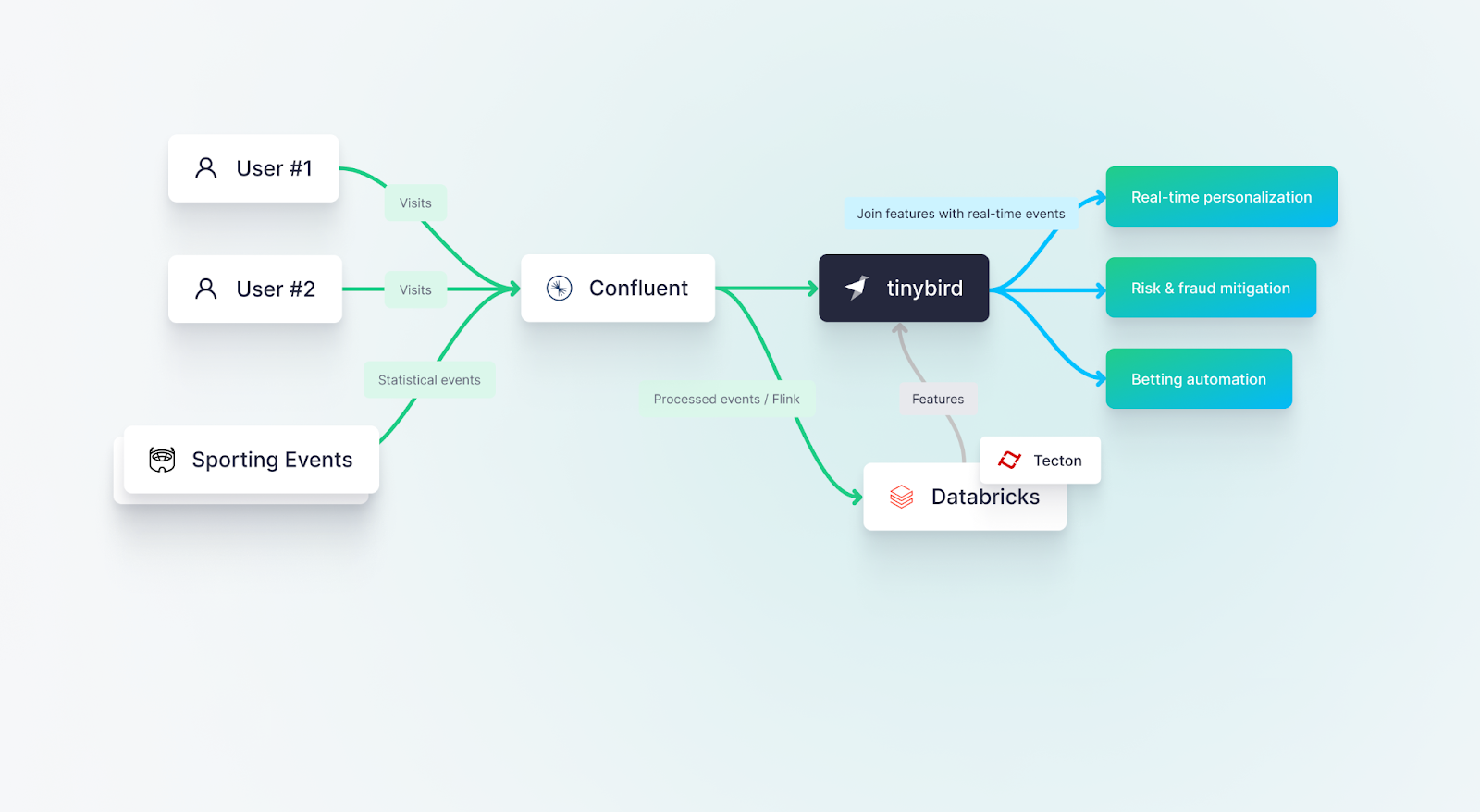
Where online retailers look to Black Friday to drive significant portions of their total revenues, online sports betting platforms bank on single sporting events with massive global audiences: the Super Bowl, NBA Finals, or Champions League for example.
One such customer of Tinybird operates in the dynamic field of online gaming, managing a complex data platform that has evolved across multiple generations of technology. From traditional RDBMS, to DeltaLake on Databricks, and now adding in real-time streaming with Confluent and Tinybird, this customer has continually adapted their platform to harness the potential of emerging technologies.
A large sports betting platform uses Tinybird as an online feature store to serve personalized betting offers, mitigate fraud risk, and automate betting line adjusments based on real-time user behavior and real-time sporting event data.
This customer uses Tinybird as an online feature store within a larger MLOps lifecycle:
- Traditional ML with Tecton on top of Databricks: The customer started with Databricks and brought in Tecton as an ML management layer for their batch machine learning platform. This setup allowed them to effectively process and analyze large volumes of static data for their gaming applications.
- Transition to Real-Time Processing: As the data feeds have become more streaming-oriented, the customer identified cases that would benefit from a switch to real-time processing. Given their past experience with building and migrating batch data platforms, they realized the value of adopting a managed-service approach for their streaming needs so they could focus more on the use cases and less on the infrastructure.
- Embracing Confluent and Tinybird: Moving towards a real-time data processing strategy, the customer integrated the capabilities of Confluent and Tinybird. Confluent offers a robust event streaming platform, built around Apache Kafka, which excels in managing real-time data feeds.
Complementing this, Tinybird empowers data scientists and engineers to rapidly query and manipulate billions of rows of data using just SQL, while delivering results at sub-second latency. Together, these platforms create a powerful and streamlined real-time data processing environment. - Advantages of Platform Diversity: The customer leverages the strengths of various open and interoperable platforms like Databricks, Confluent, and Tinybird, resulting in a robust and flexible data platform.
Each tool excels in its specific role - Databricks for large-scale data analysis and machine learning, Confluent for managing real-time data streams, and Tinybird for enabling high-speed SQL-based transformations on vast real-time datasets.
This combination lets the customer use the best tool for the job in each scenario, crucial in a rapidly evolving industry like online gaming. This integrative approach allows for a seamless flow of data and insights across the system, facilitating quick adaptations to changing requirements and maintaining a competitive edge.
In this case, the customer has chosen a proactive approach to evolving their data platform, recognizing and harnessing the power of real-time data processing with the help of services like Tinybird and Confluent. This ability to rapidly build and test features, along with rapid API integration, allows the customer to stay at the cutting edge of the online gaming industry.
Interested in Tinybird as an online feature store?
With its real-time data processing capabilities, ergonomic SQL-based feature preparation interface, and instant API layer, Tinybird delivers the core requirements for an online feature store. Combined with its serverless deployment model, Tinybird reduces the work and overhead on data and engineering teams who want to integrate online feature stores into their MLOps lifecycles. With Tinybird, these teams get a high-performance real-time database that natively integrates with batch systems while avoiding infrastructure maintenance, scaling issues, and glue code.
If you’re interested in implementing Tinybird as an online feature store, please get in touch. Our team of real-time data engineers can help guide your design, planning, and implementation so you can ship new and differentiated user experiences, faster.